-
-
Save usayamadx/9c638d9b70bc714d6dd6043fcd54085f to your computer and use it in GitHub Desktop.
| // init | |
| let xhr = new XMLHttpRequest() | |
| let domain = 'https://read.amazon.com/' | |
| let items = [] | |
| let csvData = "" | |
| // function | |
| function getItemsList(paginationToken = null) { | |
| let url = domain + 'kindle-library/search?query=&libraryType=BOOKS' + ( paginationToken ? '&paginationToken=' + paginationToken : '' ) + '&sortType=recency&querySize=50' | |
| xhr.open('GET', url, false) | |
| xhr.send() | |
| } | |
| // request result | |
| xhr.onreadystatechange = function() { | |
| switch ( xhr.readyState ) { | |
| case 0: | |
| console.log('uninitialized') | |
| break | |
| case 1: | |
| console.log('loading...') | |
| break | |
| case 4: | |
| if(xhr.status == 200) { | |
| let data = xhr.responseText | |
| data = JSON.parse(data) | |
| if(data.itemsList) { | |
| items.push(...data.itemsList) | |
| } | |
| if(data.paginationToken) { | |
| getItemsList(data.paginationToken) | |
| } | |
| } else { | |
| console.log('Failed') | |
| } | |
| break | |
| } | |
| } | |
| // action | |
| getItemsList() | |
| // to csv | |
| items.forEach(item => { | |
| csvData += '"' + item.asin + '","' + item.title + '"\n' | |
| }) | |
| window.location = 'data:text/csv;charset=utf8,' + encodeURIComponent(csvData) |
I improved upon @usayamadx logic and made a Chrome extension to solve this problem: Kindle Book List Exporter
You can now get a csv file in 1 click. No need to deal with any code or console.
Please let me know if it works for you.
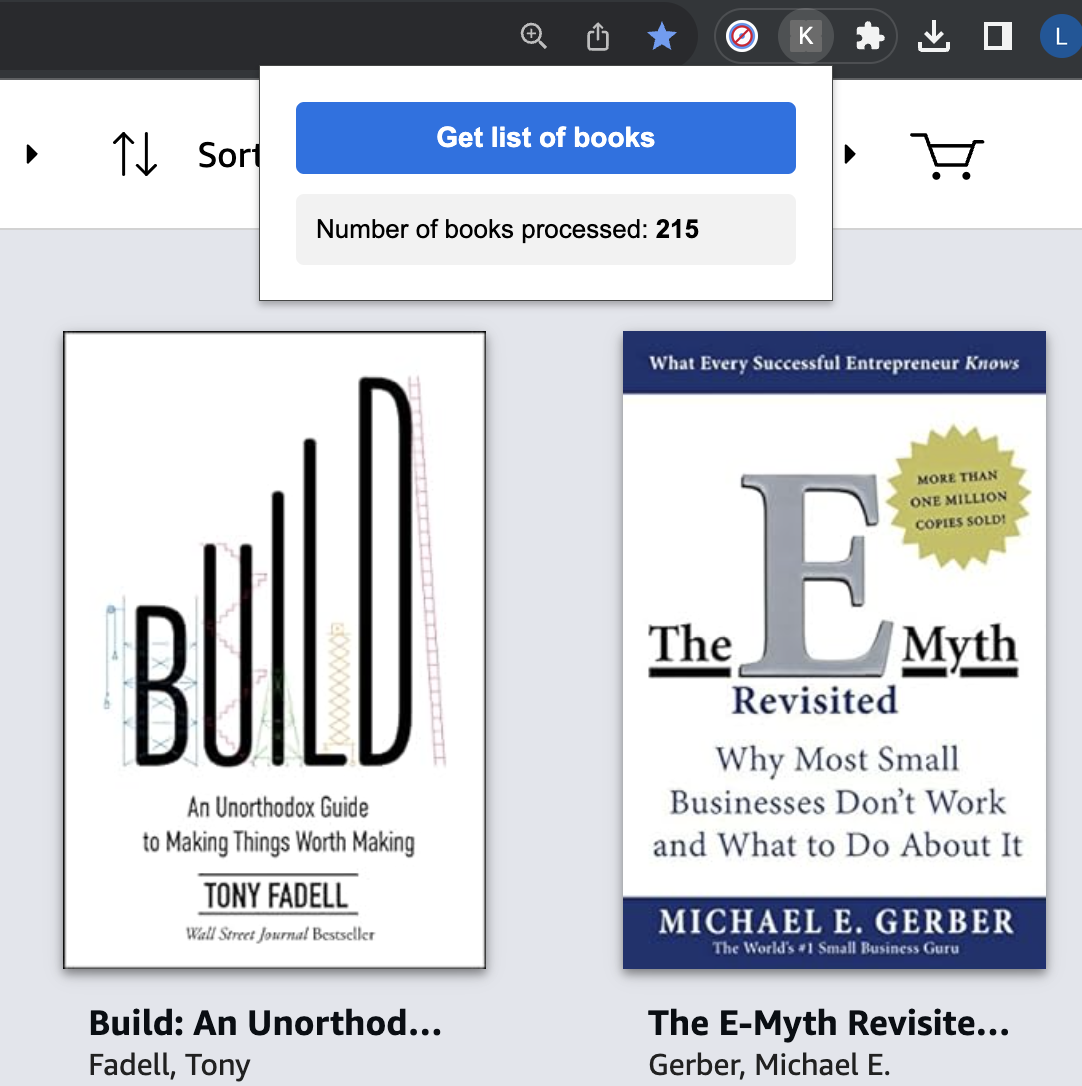
THANKS @usayamadx ! Awesome.
I, too, had something that prevented the download. I put it in a blob and it works great:
// init
let xhr = new XMLHttpRequest()
let domain = 'https://read.amazon.com/'
let items = []
let csvData = ""
const formatBook = item => '"' + item.asin + '","' + item.title + '","' + (item.authors || [])[0] + '"\n';
// function
function getItemsList(paginationToken = null) {
let url = domain + 'kindle-library/search?query=&libraryType=BOOKS' + ( paginationToken ? '&paginationToken=' + paginationToken : '' ) + '&sortType=recency&querySize=50'
xhr.open('GET', url, false)
xhr.send()
}
// request result
xhr.onreadystatechange = function() {
switch ( xhr.readyState ) {
case 0:
console.log('uninitialized')
break
case 1:
console.log('loading...')
break
case 4:
if(xhr.status == 200) {
let data = xhr.responseText
data = JSON.parse(data)
if(data.itemsList) {
items.push(...data.itemsList)
}
if(data.paginationToken) {
getItemsList(data.paginationToken)
}
} else {
console.log('Failed')
}
break
}
}
// action
getItemsList()
// to csv
items.forEach(item => {
csvData += formatBook(item);
})
const blobCSV = new Blob([csvData], {type: 'text/plain;charset=utf-8'});
blobURL = URL.createObjectURL(blobCSV);
window.location = blobURL;
thanks so much to @usayamadx - really appreciate this!