Usually, located at /usr/local/cuda/bin
$ nvprof python train_mnist.py
I prefer to use --print-gpu-trace.
$ nvprof --print-gpu-trace python train_mnist.py
On GPU machine, run
$ nvprof -o prof.nvvp python train_mnist.py
Copy prof.nvvp into your local machine
$ scp your_gpu_machine:/path/to/prof.nvvp .
Then, run nvvp (nvidia visual profiler) on your local machine:
$ nvvp prof.nvvp
It works more comfortably than X11 forwarding or something.
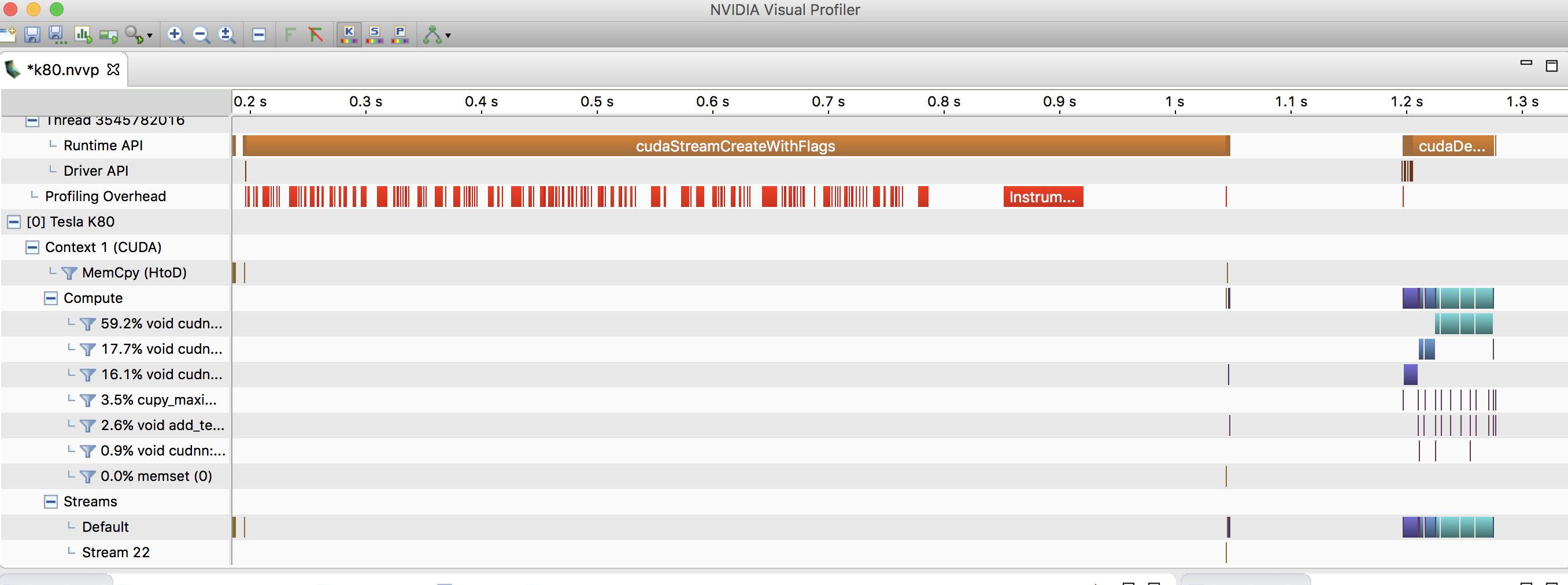

For macOS: Install cuda toolkit for macOS. nvvp is included in it. Run nvvp command on console. You don't need GPU on your macOS.
https://developer.nvidia.com/cuda-downloads