You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Development
https://raw.githack.com/[user]/[repository]/[branch]/[filename.ext]
Production (CDN)
https://rawcdn.githack.com/[user]/[repository]/[branch]/[filename.ext]
example:
https://raw.githack.com/cherkavi/javascripting/master/d3/d3-bar-chart.html
github.io
http://htmlpreview.github.io/?[full path to html page]
example
http://htmlpreview.github.io/?https://github.com/cherkavi/javascripting/blob/master/d3/d3-bar-chart.html http://htmlpreview.github.io/?https://github.com/twbs/bootstrap/blob/gh-pages/2.3.2/index.html
transfer - move data from one system to another ( SftpOperator, S3FileTransformOperator, MySqlOperator, SqliteOperator, PostgresOperator, MsSqlOperator, OracleOperator, JdbcOperator, airflow.operators.HiveOperator.... )
( don't use it for BigData - source->executor machine->destination )
sensor - waiting for arriving data to predefined location ( airflow.contrib.sensors.file_sensor.FileSensor )
has a method #poke that is calling repeatedly until it returns True
Task
An instance of an operator
Task Instance
Represents a specific run of a task = DAG + Task + Point of time
Workflow
Combination of Dags, Operators, Tasks, TaskInstances
remove examples from UI (restart)
load_examples = False
how much time a new DAGs should be picked up from the filesystem, ( dag update python file update )
min_file_process_interval = 0
dag_dir_list_interval = 60
authentication ( important for REST api 1.x.x )
auth_backend = airflow.api.auth.backend.basic_auth
AIRFLOW__API__AUTH_BACKEND=airflow.api.auth.backend.basic_auth # for version 2.0.+
catchup ( config:catchup_by_default ) or "BackFill" ( fill previous executions from start_date ) actual for scheduler only
( backfill is possible via command line )
Admin -> Connections -> postgres_default
# adjust login, password
Data Profiling->Ad Hoc Query-> postgres_default
select*from dag_run;
via PostgreConnection
clear_xcom = PostgresOperator(
task_id='clear_xcom',
provide_context=True,
postgres_conn_id='airflow-postgres',
trigger_rule="all_done",
sql="delete from xcom where dag_id LIKE 'my_dag%'",
dag=dag)
# dag list
airflow list_dags
airflow list_tasks dag_id
airflow trigger_dag my-dag
# triggering# https://airflow.apache.org/docs/apache-airflow/1.10.2/cli.html
airflow trigger_dag -c "" dag_id
airflow create dag start dag run dag
doc run
in case of removing dag (delete dag) - all metadata will me removed from database
# !!! no spaces in request body !!!
REQUEST_BODY='{"conf":{"session_id":"bff2-08275862a9b0"}}'# ec2-5-221-68-13.compute-1.amazonaws.com:8080/api/v1/dags/test_dag/dagRuns
curl --data-binary $REQUEST_BODY -H "Content-Type: application/json" -u $AIRFLOW_USER:$AIRFLOW_PASSWORD -X POST $AIRFLOW_URL"/api/v1/dags/$DAG_ID/dagRuns"
# run dag from command line
REQUEST_BODY='{"conf":{"sku":"bff2-08275862a9b0","pool_for_execution":"test_pool2"}}'
DAG_ID="test_dag2"
airflow dags trigger -c $REQUEST_BODY$DAG_ID
# * maximum number of tasks running across an entire Airflow installation
# * number of physical python processes the scheduler can run, task (processes) that running in parallel
# scope: Airflow
core.parallelism
# * max number of tasks that can be running per DAG (across multiple DAG runs)
# * number of tast instances that are running simultaneously per DagRun ( amount of TaskInstances inside one DagRun )
# scope: DAG.task
core.dag_concurrency
# * maximum number of active DAG runs, per DAG
# * number of DagRuns - will be concurrency in dag execution, don't use in case of dependencies of dag-runs
# scope: DAG.instance
core.max_active_runs_per_dag
# Only allow one run of this DAG to be running at any given time, default value = core.max_active_runs_per_dagdag=DAG('my_dag_id', max_active_runs=1)
# Allow a maximum of 10 tasks to be running across a max of 2 active DAG runs
dag = DAG('example2', concurrency=10, max_active_runs=2)
# !!! pool: the pool to execute the task in. Pools can be used to limit parallelism for only a subset of tasks
core.non_pooled_task_slot_count: number of task slots allocated to tasks not running in a pool
scheduler.max_threads: how many threads the scheduler process should use to use to schedule DAGs
celery.worker_concurrency: max number of task instances that a worker will process at a time if using CeleryExecutor
celery.sync_parallelism: number of processes CeleryExecutor should use to sync task state
# just a start worker process
airflow worker
# start with two child worker process - the same as 'worker_concurrency" in airflow.cfg
airflow worker -c 2
# default pool name: default_pool, default queue name: default
airflow celery worker --queues default
fromdatetimeimportdatetimefromairflowimportDAGfromairflow.operators.python_operatorimportPythonOperatorfromairflow.utils.timezoneimportmake_awarefromairflow.modelsimportXComdefpull_xcom_call(**kwargs):
# if you need only TaskInstance: pull_xcom_call(ti)# !!! hard-coded value execution_date=make_aware(datetime(2020, 7, 24, 23, 45, 17, 00))
xcom_values=XCom.get_many(dag_ids=["data_pipeline"], include_prior_dates=True, execution_date=execution_date)
print('XCom.get_many >>>', xcom_values)
get_xcom_with_ti=kwargs['ti'].xcom_pull(dag_id="data_pipeline", include_prior_dates=True)
print('ti.xcom_pull with include_prior_dates >>>', get_xcom_with_ti)
xcom_pull_task=PythonOperator(
task_id='xcom_pull_task',
dag=dag, # here need to set DAG python_callable=pull_xcom_call,
provide_context=True
)
GUI: Admin -> Xcoms
Should be manually cleaned up
Exchange information between multiply tasks - "cross communication".
Object must be serializable
Some operators ( BashOperator, SimpleHttpOperator, ... ) have parameter xcom_push=True - last std.output/http.response will be pushed
Some operators (PythonOperator) has ability to "return" value from function ( defined in operator ) - will be automatically pushed to XCOM
Saved in Metadabase, also additional data: "execution_date", "task_id", "dag_id"
"execution_date" means hide(skip) everything( same task_id, dag_id... ) before this date
deflog_sla_miss(dag, task_list, blocking_task_list, slas, blocking_tis):
print("SLA was missed on DAG {0}s by task id {1}s with task list: {2} which are " \
"blocking task id {3}s with task list: {4}".format(dag.dag_id, slas, task_list, blocking_tis, blocking_task_list))
...
# call back function for missed SLAwithDAG('sla_dag', default_args=default_args, sla_miss_callback=log_sla_miss, schedule_interval="*/1 * * * *", catchup=False) asdag:
t0=DummyOperator(task_id='t0')
t1=BashOperator(task_id='t1', bash_command='sleep 15', sla=timedelta(seconds=5), retries=0)
t0>>t1
should be placed into "dag" folder ( default: %AIRFLOW%/dag )
minimal dag
fromairflowimportDAGfromdatetimeimportdatetime, timedeltawithDAG('airflow_tutorial_v01',
start_date=datetime(2015, 12, 1),
catchup=False
) asdag:
print(dag)
# next string will not work !!! only for Task/Operators values !!!!print("{{ dag_run.conf.get('sku', 'default_value_for_sku') }}" )
fromairflowimportDAGfromdatetimeimportdatetime, timedeltafromairflow.operators.pythonimportPythonOperatorfromairflow.utils.datesimportdays_agodefprint_echo(**context):
print(context)
# next string will not work !!! only for Task/Operators values !!!!print("{{ dag_run.conf.get('sku', 'default_value_for_sku') }}" )
withDAG('test_dag',
start_date=days_ago(100),
catchup=False,
schedule_interval=None,
) asdag:
PythonOperator(task_id="print_echo",
python_callable=print_echo,
provide_context=True,
retries=3,
retry_delay=timedelta(seconds=30),
priority_weight=4,
weight_rule=WeightRule.ABSOLUTE, # mandatory for exected priority behavior# dag_run.conf is not working for pool !!!pool="{{ dag_run.conf.get('pool_for_execution', 'default_pool') }}",
# retries=3,# retry_delay=timedelta(seconds=30),doc_md="this is doc for task")
# still not working !!!! impossible to select pool via parametersfromairflowimportDAGfromairflow.operators.bash_operatorimportBashOperatorfromairflow.utils.datesimportdays_agodag=DAG("test_dag2", schedule_interval=None, start_date=days_ago(2))
dag_pool="{{ dag_run.conf['pool_for_execution'] }}"print(dag_pool)
parameterized_task=BashOperator(
task_id='parameterized_task',
queue='collections',
pool=f"{dag_pool}",
bash_command=f"echo {dag_pool}",
dag=dag,
)
print(f">>> {parameterized_task}")
DEFAULT_ARGS= {
'owner': 'airflow',
'depends_on_past': True,
'start_date': datetime(2015, 12, 1),
'email_on_failure': False,
'email_on_retry': False,
# 'retries': 3,# 'retry_delay': timedelta(seconds=30),
}
withDAG(DAG_NAME,
start_date=datetime(2015, 12, 1),
catchup=False,
catchup=True,
schedule_interval=None,
max_active_runs=1,
concurrency=1,
default_args=DEFAULT_ARGS
) asdag:
PythonOperator(task_id="image_set_variant",
python_callable=image_set_variant,
provide_context=True,
retries=3,
retry_delay=timedelta(seconds=30),
# retries=3,# retry_delay=timedelta(seconds=30),# https://github.com/apache/airflow/blob/866a601b76e219b3c043e1dbbc8fb22300866351/airflow/jobs/scheduler_job.py#L392# priority_weight=1 default is 1, more high will be executed earlierdoc_md="this is doc for task")
fromairflowimportDAGfromdatetimeimportdate, timedelta, datetimefromairflow.modelsimportBaseOperatorfromairflow.operators.bash_operatorimportBashOperator# airflow predefined intervalsfromairflow.utils.datesimportdays_agodef_hook_failure(error_contect):
print(error_context)
# default argument for each task in DAGdefault_arguments= {
'owner': 'airflow'
,'retries': 1
,'retry_delay': timedelta(minutes=5)
,'email_on_failure':True
,'email_on_retry':True
,'email': "[email protected]"# smtp server must be set up
,'on_failure_callback': _hook_failure
}
# when schedule_interval=None, then execution of DAG possible only with direct triggering withDAG(dag_id='dummy_echo_dag_10'
,default_args=default_arguments
,start_date=datetime(2016,1,1) # do not do that: datetime.now() # days_ago(3)
,schedule_interval="*/5 * * * *"
,catchup=False# - will be re-writed from ConfigFile !!!
,depends_on_past=False
) asdag:
# not necessary to specify dag=dag, source code inside BaseOperator:# self.dag = dag or DagContext.get_current_dag()BashOperator(task_id='bash_example', bash_command="date", dag=dag)
### connection # Conn id: data_api_connection# Conn Type: HTTP# Host: https://data-portal.devops.org# Extra: { "Content-Type": "application/json", "Cookie": "kc-access=eyJhbGci...."}fromdatetimeimporttimedelta, datetimeimportosfromtypingimportDictfromairflow.modelsimportDAGfromairflow.operators.http_operatorimportSimpleHttpOperatorfromairflow.operators.pythonimportPythonOperatorfromairflow.models.skipmixinimportSkipMixinimportloggingimportjsonDAG_NAME="data_api_call"TASK_DATA_API_CALL="data_api_call"CONNECTION_ID="data_api_connection"defprint_conf(**context):
print(context)
account_id=context["dag_run"].conf['account_id']
print(f"account_id {account_id}")
filename=context["dag_run"].conf['filename']
print(f"filename {filename}")
# alternative way of reading input parametersrequest_account="{{ dag_run.conf['account_id'] }}"withDAG(DAG_NAME,
description='collaboration with data api',
schedule_interval=None,
start_date=datetime(2018, 11, 1),
catchup=False) asdag:
defprint_input_parameters():
returnPythonOperator(task_id="print_input_variables", python_callable=print_conf, provide_context=True)
defdata_api_call(connection_id=CONNECTION_ID):
returnSimpleHttpOperator(
task_id=TASK_DATA_API_CALL
, http_conn_id=CONNECTION_ID
, method="GET"
, endpoint=f"/session-lister/v1/version?{request_account}"# data="{\"id\":111333222}"# response will be pushed to xcom with COLLABORATION_TASK_ID# , xcom_push=True
, log_response=True
, extra_options={"verify": False, "cert": None}
)
print_input_parameters() >>data_api_call()
reading settings files ( dirty way )
# settings.json should be placed in the same folder as dag description# configuration shoulhttps://github.com/cherkavi/cheat-sheet/blob/master/development-process.md#concurrency-vs-parallelismd contains: dags_folder = /usr/local/airflow/dagsdefget_request_body():
withopen(f"{str(Path(__file__).parent.parent)}/dags/settings.json", "r") asf:
request_body=json.load(f)
returnjson.dumps(request_body)
collaboration between tasks, custom functions
http operator
# api_endpoint = "{{ dag_run.conf['session_id'] }}"maprdb_read_session_metadata=SimpleHttpOperator(
task_id=MAPRDB_REST_API_TASK_ID,
method="GET",
http_conn_id="{{ dag_run.conf['session_id'] }}",
# sometimes not working and need to create external variable like api_endpoint !!!!endpoint="{{ dag_run.conf['session_id'] }}",
data={"fields": [JOB_CONF["field_name"], ]},
log_response=True,
xcom_push=True
logging, log output, print log
import logging
logging.info("some logs")
logging for task, task log
task_instance=context['ti']
task_instance.log.info("some logs for task")
execute list of tasks from external source, subdag, task loop
withDAG(default_args=DAG_DEFAULT_ARGS,
dag_id=DAG_CONFIG['dag_id'],
schedule_interval=DAG_CONFIG.get('schedule_interval', None)) asdag:
defreturn_branch(**kwargs):
""" start point (start task) of the execution ( everything else after start point will be executed ) """decision=kwargs['dag_run'].conf.get('branch', 'run_markerers')
ifdecision=='run_markerers':
return'run_markerers'ifdecision=='merge_markers':
return'merge_markers'ifdecision=='index_merged_markers':
return'index_merged_markers'ifdecision=='index_single_markers':
return'index_single_markers'ifdecision=='index_markers':
return ['index_single_markers', 'index_merged_markers']
else:
return'run_markerers'fork_op=BranchPythonOperator(
task_id='fork_marker_jobs',
provide_context=True,
python_callable=return_branch,
)
run_markerers_op=SparkSubmitOperator(
task_id='run_markerers',
trigger_rule='none_failed',
)
merge_markers_op=SparkSubmitOperator(
task_id='merge_markers',
trigger_rule='none_failed',
)
index_merged_markers_op=SparkSubmitOperator(
task_id='index_merged_markers',
trigger_rule='none_failed',
)
index_single_markers_op=SparkSubmitOperator(
task_id='index_single_markers',
trigger_rule='none_failed',
)
fork_op>>run_markerers_op>>merge_markers_op>>index_merged_markers_oprun_markerers_op>>index_single_markers_op
access to dag runs, access to dag instances, set dags state
from airflow.models import DagRun
from airflow.operators.python_operator import PythonOperator
from airflow.utils.db import provide_session
from airflow.utils.state import State
from airflow.utils.trigger_rule import TriggerRule
@provide_session
# custom parameter for operator
def stop_unfinished_dag_runs(trigger_task_id, session=None, **context):
print(context['my_custom_param'])
dros = context["ti"].xcom_pull(task_ids=trigger_task_id)
run_ids = list(map(lambda dro: dro.run_id, dros))
# identify unfinished DAG runs of rosbag_export
dr = DagRun
running_dags = session.query(dr).filter(dr.run_id.in_(run_ids), dr.state.in_(State.unfinished())).all()
if running_dags and len(running_dags)>0:
# set status failed
for dag_run in running_dags:
dag_run.set_state(State.FAILED)
print("set unfinished DAG runs to FAILED")
def dag_run_cleaner_task(trigger_task_id):
return PythonOperator(
task_id=dag_config.DAG_RUN_CLEAN_UP_TASK_ID,
python_callable=stop_unfinished_dag_runs,
provide_context=True,
op_args=[trigger_task_id], # custom parameter for operator
op_kwargs={"my_custom_param": 5}
)
fromairflow.configurationimportconf# Secondly, get the value somewhereconf.get("core", "my_key")
# Possible, set a value withconf.set("core", "my_key", "my_val")
sensor example
SensorFile(
task_id="sensor_file",
fs_conn_id="filesystem_connection_id_1", # Extras should have: {"path":"/path/to/folder/where/file/is/"}file_path="my_file_name.txt"
)
smart skip, skip task
from airflow.models import DAG
from airflow.operators.python_operator import BranchPythonOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from airflow.models.skipmixin import SkipMixin
class SelectOperator(PythonOperator, SkipMixin):
def _substract_by_taskid(self, task_list, filtered_ids):
return filter( lambda task_instance: task_instance.task_id not in filtered_ids, task_list);
def execute(self, context):
condition = super().execute(context)
# self.skip(context['dag_run'], context['ti'].execution_date, downstream_tasks)
self.log.info(">>> SelectOperator")
self.log.info(">>> Condition %s", condition)
downstream_tasks = context['task'].get_flat_relatives(upstream=False)
# self.log.info(">>> Downstream task_ids %s", downstream_tasks)
# filtered_tasks = list(self._substract_by_taskid(downstream_tasks, condition))
# self.log.info(">>> Filtered task_ids %s", filtered_tasks)
# self.skip(context['dag_run'], context['ti'].execution_date, filtered_tasks)
self.skip_all_except(context['ti'], condition)
self.log.info(">>>>>>>>>>>>>>>>>>>")
with DAG('autolabelling_example', description='First DAG', schedule_interval=None, start_date=datetime(2018, 11, 1), catchup=False) as dag:
def fork_label_job_branch(**context):
return ['index_single_labels']
fork_operator = SelectOperator(task_id=FORK_LABEL_TASK_ID, provide_context=True, python_callable=fork_label_job_branch)
Operators: They describe a single task in a workflow. Derived from BaseOperator.
Sensors: They are a particular subtype of Operators used to wait for an event to happen. Derived from BaseSensorOperator
Hooks: They are used as interfaces between Apache Airflow and external systems. Derived from BaseHook
Executors: They are used to actually execute the tasks. Derived from BaseExecutor
Admin Views: Represent base administrative view from Flask-Admin allowing to create web
interfaces. Derived from flask_admin.BaseView (new page = Admin Views + Blueprint )
Blueprints: Represent a way to organize flask application into smaller and re-usable application. A blueprint defines a collection of views, static assets and templates. Derived from flask.Blueprint (new page = Admin Views + Blueprint )
Menu Link: Allow to add custom links to the navigation menu in Apache Airflow. Derived from flask_admin.base.MenuLink
Macros: way to pass dynamic information into task instances at runtime. They are tightly coupled with Jinja Template.
# print one file from OS
adb shell cat /proc/cpuinfo
# https://source.android.com/docs/core/architecture/bootloader/locking_unlocking
adb shell getprop | grep oem
adb shell getprop sys.oem_unlock_allowed
adb shell setprop sys.oem_unlock_allowed 1
# dmesg -wH
list of all settings
adb shell service list
adb shell settings list --user current secure
adb shell settings get secure location_providers_allowed
adb shell settings get secure enabled_accessibility_services
send keyboard event
adb shell input keyevent KEYCODE_HOME
# KEYCODE_A: A# KEYCODE_B: B# KEYCODE_ENTER: Enter# KEYCODE_SPACE: Space# KEYCODE_BACK: Back button# KEYCODE_HOME: Home button
ls -l /dev/bus/usb/001/013
# crw-rw-r--+ 1 root plugdev 189, 10 Mai 21 13:50 /dev/bus/usb/001/011# if group is root, not a plugdev
sudo vim /etc/udev/rules.d/51-android.rules
SUBSYSTEM=="usb", ATTR{idVendor}=="04e8", ATTR{idProduct}=="6860", MODE="0660", GROUP="plugdev", SYMLINK+="android%n"
sudo service udev status
# download and unpack to $destionation folder https://nodejs.org/en/
destination_folder=/home/soft/node2
wget -O node.tar.xz https://nodejs.org/dist/v10.16.3/node-v10.16.3-linux-x64.tar.xz
tar -xf node.tar.xz -C $destination_folder# update /etc/environment with $destination_folder
npm config
$HOME/.npmrc - another way to extend settings per user
# list of configuration
npm config list
# full config list with default settings
npm config ls -l
# set proxy
npm config set proxy http://<username>:<pass>@proxyhost:<port>
npm config set https-proxy http://<uname>:<pass>@proxyhost:<port>
docker container with Angular attach to your current folder and build your application
cd my-new-project
# open in VisualCode just generated project ```code .```
# start locally
ng serve
# start on specific port
ng serve --port 2222
# start and open browser
ng serve --open
build a project
ng build
ng build --prod
ng build --prod --base-href http://your-url
@Component({selector: 'app-my-component',template: ` <b>my-component</b> <br/> <i>is working inline ->{{description.title+" "+description.values}}<- </i> <ul> <li *ngFor="let each of description.values; let index = index">{{ index }} {{ each }}</li> </ul> `,styleUrls: ['./my-component.component.css']})exportclassMyComponentComponent{description:objectconstructor(){this.description={title: "my custom properties",values: [5,7,9,11,13]}}}
alternative template
@Component({
selector: 'app-my-component',
template: `
<div *ngIf="description.customTemplate==true; else myAnotherTemplate">{{ description.values}}</div>
<ng-template #myAnotherTemplate>
<ul><li *ngFor="let each of description.values"> {{ each }} </li></ul>
</ng-template>
`,
styleUrls: ['./my-component.component.css']
})
export class MyComponentComponent {
description:object
constructor() {
this.description={
title: "my custom properties",
customTemplate: false,
values: [5,7,9,11,13]
}
}
}
env variable with file $ANSIBLE_CONFIG ( point out to ansible.cfg )
~/.ansible.cfg
/etc/ansible/ansible.cfg
# show current config file
ansible-config view
# description of all ansible config variables
ansible-config list
# list of possible environment variables
ansible-config dump
# example cfg file[web]
host1
host2 ansible_port=222 # defined inline, interpreted as an integer[web:vars]http_port=8080 # all members of 'web' will inherit thesemyvar=23 # defined in a :vars section, interpreted as a string
{{ hostvars[inventory_hostname]['somevar_' + other_var] }}
For ‘non host vars’ you can use the vars lookup plugin:
{{ lookup('vars', 'somevar_' + other_var) }}
- name: airflow setup for main (web server) and workershosts: alltasks:
- name: airflow hostnamedebug: msg="{{ lookup('vars', 'ansible_host') }}"
- name: variable lookupdebug: msg="lookup data {{ lookup('vars', 'ansible_host')+lookup('vars', 'ansible_host') }}"
- name: read from ini, set variableset_fact:
queues: "{{ lookup('ini', lookup('vars', 'ansible_host')+' section=queue file=airflow-'+lookup('vars', 'account_id')+'-workers.ini') }}"
- name: airflow lookupdebug: msg=" {{ '--queues '+lookup('vars', 'queues') if lookup('vars', 'queues') else '<default>' }}"
inventory file
inventory file, inventory file with variables, rules
linear ( default )
after each step waiting for all servers
free
independently for all servers - someone can finish installation significantly earlier than others
additional parameter - specify amount of servers to be executed at the time ( for default strategy only )
serial: 3
serial: 20%
serial: [5,15,20]
default value "serial" into configuration ansible.cfg
forks = 5
async execution, nowait task, command execution
not all modules support this operation
execute command in asynchronous mode ( with preliminary estimation 120 sec ),
with default poll result of the command - 10 ( seconds )
async: 120
execute command in asynchronous mode ( with preliminary estimation 120 sec ),
with poll result of the command - 60 ( seconds )
async: 120poll: 60
execute command and forget, not to wait for execution
async: 120poll: 0
execute command in asynchronous mode,
register result
checking result at the end of the file
init project ansible-galaxy, create new role, init role
execute code into your project folder './roles'
ansible-galaxy init {project/role name}
result:
./roles/{project/role name}
# Main list of tasks that the role executes
/tasks
# Files that the role deploys
/files
# Handlers, which may be used within or outside this role
/handlers
# Modules, which may be used within this role
/library
# Default variables for the role
/defaults
# Other variables for the role
/vars
# Templates that the role deploys
/templates
# Metadata for the role, including role dependencies
/meta
insert into code
roles:
- {project/role name}
all folders of the created project will be applied to your project ( tasks, vars, defaults )
in case of manual creation - only necessary folders can be created
ansible search for existing role
ansible-galaxy search {project/role name/some text}
ansible-galaxy info role-name
where "include_role" - module to run ( magic word )
where "new_application/new_role" - subfolder to role
where @group_vars/all/default/all.yaml - sub-path to yaml file with additional variables
console output with applied roles should looks like
fatal: [172.28.128.4]: FAILED! => {"msg": "Using a SSH password instead of a key is not possible because Host Key checking is enabled and sshpass does not support this. Please add this host's fingerprint to your known_hosts file to manage this host."}
# apache server installation, apache server run, web server run, webserver start
sudo su
yum update -y
yum install -y httpd
service httpd start
chkconfig httpd
chkconfig httpd on
vim /var/www/html/index.html
debian apache simple installation
#!/bin/sh
sudo apt update
sudo apt install apache2 -y
sudo ufw allow 'Apache'
sudo systemctl start apache2
# Create a new index.html file at /var/www/html/ path
echo "<html> <head><title>server 01</title> </head> <body><h1>This is server 01 </h1></body> </html>" > /var/www/html/index.html
debian apache installation
# installation
sudo su
apt update -y
apt install -y apache2
# service
sudo systemctl status apache2.service
sudo systemctl start apache2.service
# change index html
vim /var/www/html/index.html
# Uncomplicated FireWall
ufw app list
ufw allow 'Apache'
ufw status
# enable module
a2enmod rewrite
# disable module# http://manpages.ubuntu.com/manpages/trusty/man8/a2enmod.8.html
a2dismod rewrite
# enable or disable site/virtual host# http://manpages.ubuntu.com/manpages/trusty/man8/a2ensite.8.html
a2dissite *.conf
a2ensite my_public_special.conf
apache management
sudo service apache2 start
sudo service apache2 restart
flowchart LR
client --> or[ocp route] --> os[ocp service] --> op[ocp pod] --> a[apache]
cm[config map] -.->|read| a
a --> os2[ocp service 2]
a --> os3[ocp service 3]
or put the same in separated file: . /home/projects/current-project/aws.sh
# export HOME_PROJECTS_GITHUB - path to the folder with cloned repos from https://github.com/cherkaviexport AWS_SNS_TOPIC_ARN=arn:aws:sns:eu-central-1:85153298123:gmail-your-name
export AWS_KEY_PAIR=/path/to/file/key-pair.pem
export AWS_PROFILE=aws-user
export AWS_REGION=eu-central-1
# aws default value for region export AWS_DEFAULT_REGION=eu-central-1
export current_browser="google-chrome"# current_browser=$BROWSERexport aws_service_abbr="sns"functionaws-cli-doc(){if [[ -z$aws_service_abbr ]];thenecho'pls, specify the env var: aws_service_abbr'return 1
fi
x-www-browser "https://docs.aws.amazon.com/cli/latest/reference/${aws_service_abbr}/index.html"&
}
functionaws-faq(){if [[ -z$aws_service_abbr ]];thenecho'pls, specify the env var: aws_service_abbr'return 1
fi
x-www-browser "https://aws.amazon.com/${aws_service_abbr}/faqs/"&
}
functionaws-feature(){if [[ -z$aws_service_abbr ]];thenecho'pls, specify the env var: aws_service_abbr'return 1
fi
x-www-browser "https://aws.amazon.com/${aws_service_abbr}/features/"&
}
functionaws-console(){if [[ -z$aws_service_abbr ]];thenecho'pls, specify the env var: aws_service_abbr'return 1
fi
x-www-browser "https://console.aws.amazon.com/${aws_service_abbr}/home?region=$AWS_REGION"&
}
check configuration
vim ~/.aws/credentials
aws configure list
# default region will be used from env variable: AWS_REGION
aws configure get region --profile $AWS_PROFILE
aws configure get aws_access_key_id
aws configure get default.aws_access_key_id
aws configure get $AWS_PROFILE.aws_access_key_id
aws configure get $AWS_PROFILE.aws_secret_access_key
url to cli documentation, faq, collection of questions, UI
aws iam list-users
# example of adding user to group
aws iam add-user-to-group --group-name s3-full-access --user-name user-s3-bucket
# get role
aws iam list-roles
aws iam get-role --role-name $ROLE_NAME# policy find by name
POLICY_NAME=AmazonEKSWorkerNodePolicy
aws iam list-policies --query "Policies[?PolicyName=='$POLICY_NAME']"
aws iam list-policies --output text --query 'Policies[?PolicyName == `$POLICY_NAME`].Arn'# policy get by ARN
aws iam get-policy-version --policy-arn $POLICY_ARN --version-id v1
# policy list
aws iam list-attached-role-policies --role-name $ROLE_NAME# policy attach
aws iam attach-role-policy --policy-arn $POLICY_ARN --role-name $ROLE_NAME
Condition
tag of the resource can be involved in condition
create policy from error output of aws-cli command:
User is not authorized to perform
AccessDeniedException
aws iam list-groups 2>&1| /home/projects/bash-example/awk-policy-json.sh
# or just copy itecho"when calling the ListFunctions operation: Use..."| /home/projects/bash-example/awk-policy-json.sh
it is internal tunnel betweeen VPC and the rest of AWS resources
when you are creating target endpoint (to access S3, for instance) and want to use it from ec2, then add also
SSMMessagesEndpoint
EC2MessagesEndpoint
NAT
NAT Gateway (NGW) allows instances with no public IPs to access the internet.
IGW
Internet Gateway (IGW) allows instances with public IPs to access the internet.
is a service that connects an on-premises software appliance with cloud-based storage to provide seamless and secure integration between your on-premises IT environment and the AWS storage infrastructure in the AWS Cloud
TCP: 80 (HTTP)
Used by your computer to obtain the agent activation key. After successful activation, DataSync closes the agent's port 80.
TCP: 443 (HTTPS)
Used by the DataSync agent to activate with your AWS account. This is for agent activation only. You can block the endpoints after activation.
For communication between the DataSync agent and the AWS service endpoint.
API endpoints: datasync.$region.amazonaws.com
Data transfer endpoints: $taskId.datasync-dp.$region.amazonaws.com cp.datasync.$region.amazonaws.com
Data transfer endpoints for FIPS: cp.datasync-fips.$region.amazonaws.com
Agent updates: repo.$region.amazonaws.com repo.default.amazonaws.com packages.$region.amazonaws.com
TCP/UDP: 53 (DNS)
For communication between DataSync agent and the DNS server.
TCP: 22
Allows AWS Support to access your DataSync to help you with troubleshooting DataSync issues. You don't need this port open for normal operation, but it is required for troubleshooting.
UDP: 123 (NTP)
Used by local systems to synchronize VM time to the host time.
NTP
0.amazon.pool.ntp.org
1.amazon.pool.ntp.org
2.amazon.pool.ntp.org
3.amazon.pool.ntp.org
should be considered DataStorage type like ( see CommandQueryResponsibilitySegregation ):
read heavy
write heavy jdbc wrapper
there are "Database Migration Service"
PostgreSQL
!!! important during creation need to set up next parameter:
Additional configuration->Database options->Initial Database ->
default schema - postgres
!!! if you have created Public accessible DB, pls, check/create inbound rule in security group:
IPv4 PostgreSQL TCP 5432 0.0.0.0/0
CREATEDATABASEIF NOT EXISTS cherkavi_database_001 COMMENT 'csv example' LOCATION 's3://my-bucket-001/temp/';
create table
CREATE EXTERNAL TABLE IF NOT EXISTS num_sequence (id int,column_name string,column_value string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://my-bucket-001/temp/';
--- another way to create table
CREATE EXTERNAL TABLE num_sequence2 (id int,column_name string,column_value string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES ("separatorChar"=",", "escapeChar"="\\")
LOCATION 's3://my-bucket-001/temp/'
# list ec2, ec2 list, instances list
aws ec2 describe-instances --profile $AWS_PROFILE --region $AWS_REGION --filters Name=tag-key,Values=test
# example
aws ec2 describe-instances --region us-east-1 --filters "Name=tag:Name,Values=ApplicationInstance"# !!! without --filters will give you not a full list of EC2 !!!
connect to instance in private subnet, bastion approach
flowchart LR;
a[actor] -->|inventory| jb
subgraph public subnet
jb[ec2
jumpbox]
end
subgraph private subnet
s[ec2
server]
end
jb -->|inventory| s
Loading
reading information about current instance, local ip address, my ip address, connection to current instance, instance reflection, instance metadata, instance description
curl http://169.254.169.254/latest/meta-data/
curl http://169.254.169.254/latest/meta-data/instance-id
curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
curl http://169.254.169.254/latest/api/token
# public ip
curl http://169.254.169.254/latest/meta-data/public-ipv4
curl http://169.254.169.254/latest/dynamic/instance-identity/document
snapshot can be created from one ESB
snapshot can be copied to another region
volume can be created from snapshot and attached to EC2
ESB --> Snapshot --> copy to region --> Snapshot --> ESB --> attach to EC2
attach new volume
# list volumes
sudo lsblk
sudo fdisk -l
# describe volume from previous command - /dev/xvdf
sudo file -s /dev/xvdf
# !!! new partitions !!! format volume# sudo mkfs -t xfs /dev/xvdf# or # sudo mke2fs /dev/xvdf# attach volume
sudo mkdir /external-drive
sudo mount /dev/xvdf /external-drive
ELB - Elastic Load Balancer
aws_service_abbr="elb"
aws-cli-doc
aws-faq
flowchart LR;
r[Request] --> lb
l[Listener] --o lb[Load Balancer]
lr[Listener
Rule] --o l
lr --> target_group1
lr --> target_group2
lr --> target_group3
subgraph target_group1
c11[ec2]
c12[ec2]
c13[ec2]
end
subgraph target_group2
c21[ec2]
c22[ec2]
c23[ec2]
end
subgraph target_group3
c31[ec2]
c32[ec2]
c33[ec2]
end
# how to write files into /efs and they'll be available on both your ec2 instances!# on both instances:
sudo yum install -y amazon-efs-utils
sudo mkdir /efs
sudo mount -t efs fs-yourid:/ /efs
SQS - Queue Service
types: standart, fifo
aws_service_abbr="sqs"
aws-cli-doc
aws-faq
# get CLI help
aws sqs help# list queues and specify the region
aws sqs list-queues --region $AWS_REGION
AWS_QUEUE_URL=https://queue.amazonaws.com/3877777777/MyQueue
aws sqs send-message --queue-url ${QUEUE_NAME} --message-body '{"test":00001}'# status of the message - available
aws sqs receive-message --queue-url ${QUEUE_NAME}# status of the message - message in flight
RECEIPT_HANDLE=$(echo $RECEIVE_MESSAGE_OUTPUT| jq -r '.Messages[0].ReceiptHandle')
aws sqs delete-message --queue-url ${QUEUE_NAME} --receipt-handle $RECEIPT_HANDLE# status of the message - not available
# send a message
aws sqs send-message help
aws sqs send-message --queue-url $AWS_QUEUE_URL --region $AWS_REGION --message-body "my test message"# receive a message
aws sqs receive-message help
aws sqs receive-message --region $AWS_REGION --queue-url $AWS_QUEUE_URL --max-number-of-messages 10 --visibility-timeout 30 --wait-time-seconds 20
# delete a message ( confirmation of receiving !!! )
aws sqs delete-message help
aws sqs receive-message --region us-east-1 --queue-url $AWS_QUEUE_URL --max-number-of-messages 10 --visibility-timeout 30 --wait-time-seconds 20
aws sqs delete-message --receipt-handle $MESSAGE_ID1$MESSAGE_ID2$MESSAGE_ID3 --queue-url $AWS_QUEUE_URL --region $AWS_REGION
EventBridge
Event hub that receives, collects, filters, routes events ( message with body and head ) based on rules
to receiver back, to another serviceS, to apiS ...
Similar to SQS but wider.
Offers comprehensive monitoring and auditing capabilities.
terms
Event
A JSON-formatted message that represents a change in state or occurrence in an application or system
Event bus
A pipeline that receives events from various sources and routes them to targets based on defined rules
Event source
The origin of events, which can be AWS services, custom applications, or third-party SaaS providers
Event pattern
A JSON-based structure that is used in rules to define criteria for matching events
Schema
A structured definition of an event's format, which can be used for code generation and validation
Rule
Criteria that are used to match incoming events and determine how they should be processed or routed
Archive
A feature that makes it possible for you to store events for later analysis or replay
Target
The destination where matched events are sent, which offers options for event transformation, further processing, and reliable delivery mechanisms, including dead-letter queues
### lambda all logs
x-www-browser "https://"$AWS_REGION".console.aws.amazon.com/cloudwatch/home?region="$AWS_REGION"#logs:### lambda part of logsx-www-browser "https://"$AWS_REGION".console.aws.amazon.com/cloudwatch/home?region="$AWS_REGION"#logStream:group=/aws/lambda/"$LAMBDA_NAME";streamFilter=typeLogStreamPrefix"
# https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-install.html
pip3 install aws-sam-cli
sam --version
sam cli init
sam deploy --guided
Python Zappa
virtualenv env
source env/bin/activate
# update your settings https://github.com/Miserlou/Zappa#advanced-settings
zappa init
zappa deploy dev
zappa update dev
aws_ecr_repository_name=udacity-cherkavi
aws ecr create-repository --repository-name $aws_ecr_repository_name --region $AWS_REGION# aws ecr delete-repository --repository-name udacity-cherkavi# list of all repositories
aws ecr describe-repositories
# list of all images in repository
aws ecr list-images --repository-name $aws_ecr_repository_name
^|------------------------------|------------|
T| DirectConnect/StorageGateway | Snowmobile |
i|------------------------------|------------|
m| transfer to S3 directly | Snowball |
e|------------------------------|------------|
size of data --->
AWS Server Migration Service
requirements
available for: VMware vSphere, Microsoft Hyper-V, Azure VM
replicate to AmazonMachineImages ( EC2 )
using connector - BSDVM that you should install into your environment
AWS Migration Hub
Amazon CloudEndure,
AWS ServerMigrationService
AWS DatabaseMigrationService
Application Discovery Service
Application Discovery Agents
Application Discovery Service
perform discovery and collect data
agentless ( working with VMware vCenter )
agent-based ( collecting processes into VM and exists network connections )
Migration steps
Disover current infrastructure
Experiment with services and copy of data
Iterate with another experiment ( using other services )
Deploying to AWS
Percona XtraBackup
installation
wget https://repo.percona.com/apt/percona-release_latest.$(lsb_release -sc)_all.deb
sudo dpkg -i percona-release_latest.$(lsb_release -sc)_all.deb
sudo apt-get update
# MySQL 5.6, 5.7; for MySQL 8.0 - XtraBackup 8.0
sudo apt-get -y install percona-xtrabackup-24
bigsql/bin start
bigsql/bin stop
bigsql/bin status
configuration
bigsql-conf.xml
switch on compatability mode
use Big SQL 1.0 into Big SQL
set syshadoop.compatability_mode=1;
Data types
Declared type
SQL type
Hive type
using strings
avoid to use string - default value 32k
change default string length
set hadoop property bigsql.string.size=128
use VARCHAR instead of
datetime ( not date !!! )
2003-12-23 00:00:00.0
boolean
create schema
create schema "my_schema";
use "my_schema"
drop schema "my_schema" cascade;
create table ( @see hive.md )
create hadoop table IF NOT EXISTS my_table_into_my_schema ( col1 int not null primary key, col2 varchar(50))
row format delimited
fields terminated by ','
LINES TERMINATED by '\n'
escaped BY '\\',
null defined as '%THIS_IS_NULL%' s
stored as [<empty>, TEXT, BINARY] SEQUENCEFILE;
-- PARQUETFILE
-- ORC
-- RCFILE
-- TEXTFILE
avro table creation:
insert
insert values (not to use for prod) - each command will create its personal file with records
insert into my_table_into_my_schema values (1,'first'), (2,'second'), (3,'third');
file insert - copy file into appropriate folder ( with delimiter between columns )
link anchor, link to text, highlight text on the page, find text on the page, text fragments
x-www-browser https://github.com/cherkavi/cheat-sheet/blob/master/architecture-cheat-sheet.md#:~:text=Architecture cheat sheet&text=Useful links
# also possible to say prefix before the text
x-www-browser https://github.com/cherkavi/cheat-sheet/blob/master/architecture-cheat-sheet.md#:~:text=Postponing,%20about
# aslo possible to say previx and suffix around the destination text
> kubectl get deployments -n crossplane-system
NAME READY UP-TO-DATE AVAILABLE
crossplane 1/1 1 1
crossplane-rbac-manager 1/1 1 1
Resources
flowchart LR
c[crossplane] ---o k[k8s]
c <-.->|r/w| e[etcd]
p[providers] --o c
p --> cr[composition
resource] --> m[managed
resource]
p --> cm[composition] --> cr
pip3 install dbt-core
dbt --help
# init new project in current folder
dbt init
# run dbt models in the project
dbt run
# run tests
dbt tests
## target database manipulations# clean target db
dbt clean
# create snapshot of the data
dbt snapshot
# load seeds data
dbt seed
# new group in sudo for docker
sudo groupadd docker
# add current user into docker group
sudo usermod -aG docker $USER# restart service
sudo service docker restart
# restart daemon
systemctl daemon-reload
# refresh sudo
sudo reboot
Docker Issue:
Couldn't connect to Docker daemon at http+docker://localhost - is it running?
sudo usermod -a -G docker $USER
sudo systemctl enable docker # Auto-start on boot
sudo systemctl start docker # Start right now# reboot
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock
logout and login again
standard_init_linux.go:228: exec user process caused: exec format error
change Docker file with additional lines ( not necessary, only for earlier docker version )
ARG rsync_proxy
ENV rsync_proxy $rsync_proxy
ARG http_proxy
ENV http_proxy $http_proxy
ARG no_proxy
ENV no_proxy $no_proxy
ARG ftp_proxy
ENV ftp_proxy $ftp_proxy
...
# at the end of file
unset http_proxy
unset ftp_proxy
unset rsync_proxy
unset no_proxy
login, logout
docker login -u cherkavi -p `oc whoami -t` docker-registry.local.org
docker logout docker-registry.local.org
# for artifactory you can use token as password
Do not automatically restart the container. (the default)
on-failure
Restart the container if it exits due to an error, which manifests as a non-zero exit code.
always
Always restart the container if it stops. If it is manually stopped, it is restarted only when Docker daemon restarts or the container itself is manually restarted. (See the second bullet listed in restart policy details)
unless-stopped
Similar to always, except that when the container is stopped (manually or otherwise), it is not restarted even after Docker daemon restarts.
map volume ( map folder )
-v {host machine folder}:{internal folder into docker container}:{permission}
connecting containers via host, localhost connection, shares the host network stack and has access to the /etc/hosts for network communication, host as network share host network share localhost network
--network="bridge" :
'host': use the Docker host network stack
'bridge': create a network stack on the default Docker bridge
'none': no networking
'container:<name|id>': reuse another container's network stack
'<network-name>|<network-id>': connect to a user-defined network
mount folder, map folder, mount directory, map directory multiple directories
working_dir="/path/to/working/folder"
docker run --volume $working_dir:/work -p 6900-6910:5900-5910 --name my_own_container -it ubuntu:18.04 /bin/sh
# !!! path to the host folder should be absolute !!! attach current folder
docker run --entrypoint="" --name airflow_custom_local --interactive --tty --publish 8080:8080 --volume `pwd`/logs:/opt/airflow/logs --volume `pwd`/dags:/opt/airflow/dags airflow_custom /bin/sh
Volumes
create volume
docker volume create {volume name}
inspect volume, check volume, read data from volume, inspect data locally
# inspect Mountpoint
ls -la /var/snap/docker/common/var-lib-docker/volumes/cd72b76daf3c66de443c05dfde77090d5e5499e0f2a0024f9ae9246177b1b86e/_data
list of all volumes
docker volume ls
using volume
docker run {name of image} -v {volume name}:/folder/inside/container
docker run {name of image} -mount source={volume name},target=/folder/inside/container
Inspection
show all containers that are running
docker ps
show all containers ( running, stopped, paused )
docker ps -a
show container with filter, show container with format
The following packages have unmet dependencies:
docker-ce : Depends: libseccomp2 (>= 2.3.0) but 2.2.3-3ubuntu3 is to be installed
E: Unable to correct problems, you have held broken packages.
Error response from daemon: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io on 160.55.52.52:8080: no such host
build error
W: Failed to fetch http://archive.ubuntu.com/ubuntu/dists/xenial/InRelease Could not resolve 'archive.ubuntu.com'
W: Failed to fetch http://archive.ubuntu.com/ubuntu/dists/xenial-updates/InRelease Could not resolve 'archive.ubuntu.com'
# Build node appFROM node:16 as build
WORKDIR /src
RUN yarn install --immutable
RUN yarn run web:build:prod
# start file serviceFROM caddy:2.5.2-alpine
WORKDIR /src
COPY --from=build /src/web/.webpack ./
EXPOSE 80
CMD ["caddy", "file-server", "--listen", ":80"]
build useful commands
command
description
FROM
Sets the base image, starting image to build the container, must be first line
MAINTAINER
Sets the author field of the generated images
RUN
Execute commands in a new layer on top of the current image and commit the results
CMD
Allowed only once (if many then last one takes effect)
LABEL
Adds metadata to an image
EXPOSE
Informs container runtime that the container listens on the specified network ports at runtime
ENV
Sets an environment variable
ADD
Copy new files, directories, or remote file URLs from into the filesystem of the container
COPY
Copy new files or directories into the filesystem of the container
ENTRYPOINT
Allows you to configure a container that will run as an executable
VOLUME
Creates a mount point and marks it as holding externally mounted volumes from native host or other containers
USER
Sets the username or UID to use when running the image
WORKDIR
Sets the working directory for any RUN, CMD, ENTRYPOINT, COPY, ADD commands
ARG
Defines a variable that users can pass at build-time to the builder using --build-arg
ONBUILD
Adds an instruction to be executed later, when the image is used as the base for another build
STOPSIGNAL
Sets the system call signal that will be sent to the container to exit
Use RUN instructions to build your image by adding layers
Use ENTRYPOINT to CMD when building executable Docker image and you need a command always to be executed.
( ENTRYPOINT can be re-writed from command-line: docker run -d -p 80:80 --entrypoint /bin/sh alipne )
Use CMD if you need to provide extra default arguments that could be overwritten from command line when docker container runs.
Use CMD if you need to provide default arguments that could be overwritten from command line when docker container runs.
for a starting points ( FROM ) using -alpine or -scratch images, for example: "FROM python:3.6.1-alpine"
Each line in a Dockerfile creates a new layer, and because of the layer cache, the lines that change more frequently, for example, adding source code to an image, should be listed near the bottom of the file.
CMD will be executed after COPY
microdnf - minimal package manager
FROM python:3.6.1-alpine
RUN pip install flask
CMD ["python","app.py"]
COPY app.py /app.py
create user and group, create group
RUN groupadd -g 2053 r-d-ubs-technical-user
RUN useradd -ms /bin/bash -m -u 2056 -g 2053 customer2description
# activate user
USER customer2description
for downloading external artifacts need to use ADD command, COPY vs ADD
communication with dockerd via REST & Python & CLI
docker sdk rest api
docker_api_version=1.41
# get list of containers
curl --unix-socket /var/run/docker.sock http://localhost/v${docker_api_version}/containers/json
# start container by image id
docker_image_id=050db1833a9c
curl --unix-socket /var/run/docker.sock -X POST http://localhost/v${docker_api_version}/containers/${docker_image_id}/start
The routing mesh built into Docker Swarm means that any port that is published at the service level will be exposed on every node in the swarm. Requests to a published service port will be automatically routed to a container of the service that is running in the swarm.
docker daemon
## start docker daemon process
sudo dockerd
# start in debug mode
sudo dockerd -D
# start in listening mode
sudo dockerd -H 0.0.0.0:5555
# using client with connection to remove docker daemon
docker -H 127.0.0.1:5555 ps
issues
docker image contain your local proxy credentials, remove credentials from docker container
container that you built locally contains your proxy credentials
solution
before 'docker login' need change file ~/.docker/config.json remove next block
"credsStore": "secretservice"
docker instance issue
#apt install software-properties-common
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package software-properties-common
solution
need to execute 'update' before new package installation
apt update
and also helpful
apt install -y software-properties-common
docker build command issue
issue
FROM cc.ubsgroup.net/docker/builder
RUN mkdir /workspace
COPY dist/scenario_service.pex /workspace/scenario_service.pex
WORKDIR /workspace
docker build -t local-scenario --file Dockerfile-scenario-file .# COPY/ADD failed: stat /var/lib/docker/tmp/docker-builder905175157/scenario_service.pex: no such file or directory
but file exists and present in proper place
solution 1
check your .dockerignore file for ignoring your "dist" or even worse "*" files :
# ignore all files
*
solution 2
FROM cc.ubsgroup.net/docker/builder
RUN mkdir /workspace
COPY scenario_service.pex /workspace/scenario_service.pex
WORKDIR /workspace
Drill client ( connects to a Foreman, submits SQL statements, and receives results )
Foreman ( DrillBit server selected to maintain your session )
worker Drillbit servers ( do the actual work of running your query )
ZooKeeper server ( which coordinates the Drillbits within the Drill cluster and keep configuration )
necessary to register of all Drillbit servers
LifeCycle
Parse the SQL statement into an internal parse tree ( Apache Calcite )
check sql query
Perform semantic analysis on the parse tree by resolving names the selected data‐
base, against the schema (set of tables) in that database ( Apache Calcite )
check "database/table" names ( not columns, not columns types, schema-on-read system !!! )
Convert the SQL parse tree into a logical plan, which can be thought of as a block
diagram of the major operations needed to perform the given query. ( Apache Calcite )
Convert the logical plan into a physical plan by performing a cost-based optimi‐
zation step that looks for the most efficient way to execute the logical plan.
Drill Web Console -> QueryProfile
Convert the physical plan into an execution plan by determining how to distrib‐
ute work across the available worker Drillbits.
Distribution
Major fragment - set of operators that can be done without exchange between DrillBits and grouped into a thread
Minor fragment - slice of Major Fragment ( for instance reading one file from folder ), distribution unit
Data affinity - place minor fragment to the same node where is data placed ( HDFS/MapR, where compute and storage are separate, like cloud - randomly )
Collect all results (Minor fragments) on Foreman, provide results to client
start embedded
# install drill
## https://drill.apache.org/download/
mkdir /home/projects/drill
cd /home/projects/drill
curl -L 'https://www.apache.org/dyn/closer.lua?filename=drill/drill-1.19.0/apache-drill-1.19.0.tar.gz&action=download' | tar -vxzf -
or
sudo apt-get install default-jdk
curl -o apache-drill-1.6.0.tar.gz http://apache.mesi.com.ar/drill/drill-1.6.0/apache-drill-1.6.0.tar.gz
tar xvfz apache-drill-1.6.0.tar.gz
cd apache-drill-1.6.0
Error text: Current default schema: No default schema selected
check your folder for existence ( maybe you haven't mapped in your docker container )
SHOW SCHEMAS;
SELECT*FROMsys.boot;
use dfs;
configuration in file: storage-plugins-override.conf
# This file involves storage plugins configs, which can be updated on the Drill start-up.# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md for more information."storage": {
dfs: {type: "file",connection: "file:///",workspaces: {"wondersign": {
"location": "/home/projects/wondersign",
"writable": false,
"defaultInputFormat": "json",
"allowAccessOutsideWorkspace": false
},
},
formats: {"parquet": {
"type": "parquet"
},
"json": {
"type": "json"extensions: [""],
}
},enabled: true}}
# start recording console to file, write output!record out.txt
# stop recording
record
drill querying data
-- execute it first
show databases; -- show schemas;--------------------------------------------select sessionId, isReprocessable from dfs.`/mapr/dp.prod.zurich/vantage/data/store/processed/0171eabfceff/reprocessable/part-00000-63dbcc0d1bed-c000.snappy.parquet`;
-- or even select sessionId, isReprocessable from dfs.`/mapr/dp.prod.zurich/vantage/data/store/processed/*/*/part-00000-63dbcc0d1bed-c000.snappy.parquet`;
-- with functions
to_char(to_timestamp(my_column), 'yyyy-MM-dd HH:mm:ss')
to_number(concat('0', mycolumn),'#')
-- local filesystemSELECT filepath, filename, sku FROM dfs.`/home/projects/dataset/kaggle-data-01`where sku is not null;
SELECT filepath, filename, sku FROMdfs.root.`/kaggle-data-01`where sku is not nullSELECT filepath, filename, t.version, t.car_info.boardnet_version catinfo FROMdfs.root.`/file_infos` t;
SELECTt.row_data.start_time start_time, t.row_data.end_time end_time FROM ( SELECT flatten(file_info) AS row_data fromdfs.root.`/file_infos/765f3c13-6c57-4400-acee-0177ca43610b/Metadata/file_info.json` ) AS t;
-- local file system complex query with inner!!! joinSELECThvl.startTime, hvl.endTime, hvl.labelValueDouble, hvl2.labelValueDoubleFROM dfs.`/vantage/data/store/95933/acfb-01747cefa4a9/single_labels/host_vehicle_latitude` hvl INNER JOIN dfs.`/vantage/data/store/95933/acfb-01747cefa4a9/single_labels/host_vehicle_longitude` hvl2
ONhvl.startTime=hvl2.startTimeWHEREhvl.startTime>=1599823156000000000ANDhvl.startTime<=1599824357080000000
!!! important: you should avoid colon ':' symbol in path ( explicitly or implicitly with asterix )
# common part
ELASTIC_HOST=https://elasticsearch-label-search-prod.apps.vantage.org
INDEX_NAME=ubs-single-autolabel
check connection
# version info
curl -X GET $ELASTIC_HOST# health check
curl -H "Authorization: Bearer $TOKEN" -X GET $ELASTIC_HOST/_cluster/health?pretty=true
curl -X GET $ELASTIC_HOST/_cluster/health?pretty=true
curl -X GET $ELASTIC_HOST/_cluster/health?pretty=true&level=shards
curl -X GET $ELASTIC_HOST/$INDEX_NAME
check user
curl -s --user "$USER_ELASTIC:$USER_ELASTIC_PASSWORD" -X GET $ELASTIC_HOST/_security/user/_privileges
curl -s --user "$USER_ELASTIC:$USER_ELASTIC_PASSWORD" -X GET $ELASTIC_HOST/_security/user
curl -s --user "$USER_ELASTIC:$USER_ELASTIC_PASSWORD" -X GET $ELASTIC_HOST/_security/user/$USER_ELASTIC
obtain bearer token
curl -s --user "$USER_ELASTIC:$USER_ELASTIC_PASSWORD" -X GET $ELASTIC_HOST/token
index
create index mapping
Info: if your index or id has space ( special symbol ) you should replace it with %20 ( http escape )
index info
# all indexes
curl -X GET $ELASTIC_HOST/_cat/indices | grep ubs | grep label
# count records by index
curl -X GET $ELASTIC_HOST/_cat/count/$INDEX_NAME
org.elasticsearch.hadoop.rest.EsHadoopRemoteException: illegal_argument_exception: Can't merge because of conflicts: [Cannot update excludes setting for [_source]]
check your index & type - something wrong with creation
if you want to see for your pull request 'git diff' in raw text - just add '.diff" prefix at the end of the pull request number like 'https://gihub.com/.....lambdas/pull/95.diff'
git checkout my_branch
# take a look into your local changes, for instance we are going to squeeze 4 commits
git reset --soft HEAD~4
# in case of having external changes and compress commits: git rebase --interactive HEAD~4
git commit # your files should be staged before
git push --force-with-lease origin my_branch
check hash-code of the branch, show commit hash code
git rev-parse "remotes/origin/release-6.0.0"
print current hashcode commit hash last commit hash, custom log output
git rev-parse HEAD
git log -n 1 --pretty=format:'%h'> /tmp/gitHash.txt
difference between branch and current file ( compare file with file in branch )
git diff master -- myfile.cs
difference between commited and staged
git diff --staged
difference between two branches, list of commits list commits, messages list of messages between two commits
git rev-list master..search-client-solr
# by author
git rev-list --author="Vitalii Cherkashyn" item-598233..item-530201
# list of files that were changed
git show --name-only --oneline `git rev-list --author="Vitalii Cherkashyn" item-598233..item-530201`# list of commits between two branches
git show --name-only --oneline `git rev-list d3ef784e62fdac97528a9f458b2e583ceee0ba3d..eec5683ed0fa5c16e930cd7579e32fc0af268191`
git tag -a $newVersion -m 'deployment_jenkins_job'
push tags only
git push --tags $remoteUrl
show tags
# show current tags show tags for current commit
git show
git describe --tags
git describe
# fetch tags
git fetch --all --tags -prune
# list of all tags list tag list
git tag
git tag --list
git show-ref --tags
# tag checkout tag
git tags/1.0.13
PATH_TO_FOLDER=/home/projects/bash-example
# remote set
git remote add local-hdd file://${PATH_TO_FOLDER}/.git
# commit all files
git add *; git commit --message 'add all files to git'# set tracking branch
git branch --set-upstream-to=local-hdd/master master
# avoid to have "refusing to merge unrelated histories"
git fetch --all
git merge master --allow-unrelated-histories
# merge all conflicts# in original folder move to another branch for avoiding: branch is currently checked out
git push local-hdd HEAD:master
# go to origin foldercd$PATH_TO_FOLDER
git reset --soft origin/master
git diff
using authentication token personal access token, git remote set, git set remote
example of using github.com
# Settings -> Developer settings -> Personal access tokens# https://github.com/settings/apps
git remote set-url origin https://$GIT_TOKEN@github.com/cherkavi/python-utilitites.git
# in case of Error: no such remote
git remote add origin https://$GIT_TOKEN@github.com/cherkavi/python-utilitites.git
# in case of asking username & password - check URL, https prefix, name of the repo.... # in case of existing origin, when you add next remote - change name origin to something else like 'origin-gitlab'/'origin-github'
git remote add bitbucket https://[email protected]/cherkavi/python-utilitites.git
git pull bitbucket master --allow-unrelated-histories
git archive --remote=ssh://https://github.com/cherkavi/cheat-sheet HEAD jenkins.md
update remote branches, when you see not existing remote branches
git remote update origin --prune
worktree
worktree it is a hard copy of existing repository but in another folder
all worktrees are connected
# list of all existing wortrees
git worktree list
# add new worktree list
git worktree add $PATH_TO_WORKTREE$EXISTING_BRANCH# add new worktree with checkout to new branch
git worktree add -b $BRANCH_NEW$PATH_TO_WORKTREE# remove existing worktree, remove link from repo
git worktree remove $PATH_TO_WORKTREE
git worktree prune
if you are using SSH access to git, you should specify http credentials ( lfs is using http access ), to avoid possible errors: "Service Unavailable...", "Smudge error...", "Error downloading object"
git config --global credential.helper store
file .gitconfig will have next section
[credential]
helper = store
file ~/.git-credentials ( default from previous command ) should contains your http(s) credentials
# create bare repo file:///home/projects/bmw/temp/repo# for avoiding: error: failed to push some refs to
mkdir /home/projects/bmw/temp/repo
cd /home/projects/bmw/temp/repo
git init --bare
# or git config --bool core.bare true# clone to copy #1
mkdir /home/projects/bmw/temp/repo2
cd /home/projects/bmw/temp/repo2
git clone file:///home/projects/bmw/temp/repo
# clone to copy #1
mkdir /home/projects/bmw/temp/repo3
cd /home/projects/bmw/temp/repo3
git clone file:///home/projects/bmw/temp/repo
configuration for proxy server, proxy configuration
# See http://jorisroovers.github.io/gitlint/rules/ for a full description.[general]ignore=T3,T5,B1,B5,B7
[title-match-regex]regex=^[A-Z].{0,71}[^?!.,:; ]
advices
migration from another git repo
big monorepo increase git responsivnes
git config core.fsmonitor true
git config core.untrackedcache truetime git status
# GIT_URL=https://github.ubsbank.ch# GIT_API_URL=$GIT_URL/api/v3
GIT_API_URL=https://api.github.com
# get access to repo # Paging: !!! Check if there is a 'Link' header with a 'rel="next"' linkfunctiongit-api-get(){
curl -s --request GET --header "Authorization: Bearer $GIT_TOKEN_REST_API" --url "${GIT_API_URL}${1}"
}
# list of all accessing endpoints
git-api-get
# user info
GIT_USER_NAME=$(git-api-get /user | jq -r .name)echo$GIT_USER_NAME# repositories
git-api-get /users/$GIT_USER_NAME/repos
# git rest with page size
git-api-get /users/${GIT_USER}/repos?per_page=100 | jq ".[] | [.fork, .clone_url]"
GIT_REPO_OWNER=swh
GIT_REPO_NAME=data-warehouse
git-api-get /repos/$GIT_REPO_OWNER/$GIT_REPO_NAME# pull requests
git-api-get /repos/$GIT_REPO_OWNER/$GIT_REPO_NAME/pulls
PULL_REQUEST_NUMBER=20203
# pull request info
git-api-get /repos/$GIT_REPO_OWNER/$GIT_REPO_NAME/pulls/$PULL_REQUEST_NUMBER# | jq -c '[.[] | {ref:.head.ref, body:.body, user:.user.login, created:.created_at, updated:.updated_at, state:.state, draft:.draft, reviewers_type:[.requested_reviewers[].type], reviewers_login:[.requested_reviewers[].login], request_team:[.requested_teams[].name], labels:[.labels[].name]}]'# pull request files
git-api-get /repos/$GIT_REPO_OWNER/$GIT_REPO_NAME/pulls/$PULL_REQUEST_NUMBER/files | jq .[].filename
# search for pull request
ISSUE_ID=MAGNUM-1477
# use + sign instead of space
SEARCH_STR="is:pr+${ISSUE_ID}"
curl -s --request GET --header "Authorization: Bearer $GIT_TOKEN_REST_API" --url "${GIT_API_URL}/search/issues?q=${SEARCH_STR}&sort=created&order=asc"# print all files by pull request
ISSUE_ID=$1
SEARCH_STR="is:pr+${ISSUE_ID}"
PULL_REQUESTS=(`curl -s --request GET --header "Authorization: Bearer $GIT_TOKEN_REST_API" --url "${GIT_API_URL}/search/issues?q=${SEARCH_STR}&sort=created&order=asc"| jq .items[].number`)
# Iterate over all elements in the arrayforPULL_REQUEST_NUMBERin"${PULL_REQUESTS[@]}";doecho"------$GIT_URL/$GIT_REPO_OWNER/$GIT_REPO_NAME/pull/$PULL_REQUEST_NUMBER------"
curl -s --request GET --header "Authorization: Bearer $GIT_TOKEN_REST_API" --url ${GIT_API_URL}/repos/$GIT_REPO_OWNER/$GIT_REPO_NAME/pulls/$PULL_REQUEST_NUMBER/files | jq .[].filename
echo"--------------------"done
## create token with UI
x-www-browser https://github.com/settings/personal-access-tokens/new
## list of all tokens
x-www-browser https://github.com/settings/tokens
export GITHUB_TOKEN=$GIT_TOKEN
http://htmlpreview.github.io/?[full path to html page]
http://htmlpreview.github.io/?https://github.com/cherkavi/javascripting/blob/master/d3/d3-bar-chart.html
http://htmlpreview.github.io/?https://github.com/twbs/bootstrap/blob/gh-pages/2.3.2/index.html
git find bad commit, check bad commits in the log
git bisect start.
git bisect bad [commit].
git bisect good [commit].
# git bisect bad # mark commit as bad# git bisect good # mark commit as good
git bisect run my_script my_script_arguments # check negative/positive answer
git bisect visualize
git bisect reset
gh auth login --hostname $GIT_HOST
gh auth status
WORKFLOW_FILE_NAME=tools.yaml
gh workflow list
gh workflow view --ref $GIT_BRANCH_NAME$WORKFLOW_FILE_NAME
gh workflow run $WORKFLOW_FILE_NAME --ref $GIT_BRANCH_NAME
gh run list --workflow=$WORKFLOW_NAME# run workflow by name from last branch
gh workflow run $WORKFLOW_FILE_NAME --ref $(git branch --show-current)# print out last log output of the workflow by name
gh run view --log $(gh run list --json databaseId --jq '.[0].databaseId')
gh variable list
gh variable set$VARIABLE_NAME --body $VARIABLE_VALUE# search pull request via CLI, search not opened pull requests
gh pr list -S 'author:cherkavi is:merged'
# Janus server
docker rm janusgraph-default
docker run --name janusgraph-default janusgraph/janusgraph:latest
# --port 8182:8182# Gremlin console in separate docker container
docker run --rm --link janusgraph-default:janusgraph -e GREMLIN_REMOTE_HOSTS=janusgraph -it janusgraph/janusgraph:latest ./bin/gremlin.sh
Gremlin console
Embedded connection ( local )
// with local connection
graph =TinkerGraph.open()
// g = traversal().withEmbedded(graph)
graph.features()
g = graph.traversal()
remote connection with submit
// connect to database, during the start should be message in console like: "plugin activated: tinkerpop.server"
:remote connect tinkerpop.server conf/remote.yaml
// check connection
:remote
// --------- doesn't work:// config = new PropertiesConfiguration()// config.setProperty("clusterConfiguration.hosts", "127.0.0.1");// config.setProperty("clusterConfiguration.port", 8182);// config.setProperty("clusterConfiguration.serializer.className", "org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV1d0");// ioRegistries = org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry// config.setProperty("clusterConfiguration.serializer.config.ioRegistries", ioRegistries); // (e.g. [ org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry) ]// config.setProperty("gremlin.remote.remoteConnectionClass", "org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection");// config.setProperty("gremlin.remote.driver.sourceName", "g");// graph = TinkerGraph.open(config)// --------- doesn't work:// graph = EmptyGraph.instance().traversal().withRemote(config);// g = graph.traversal()
remote connection without submit
import staticorg.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;
g = traversal().withRemote("conf/remote-graph.properties");
??? doesn't work with connecting points
// with remote connection
cluster =Cluster.build().addContactPoint('127.0.0.1').create()
client = cluster.connect()
// g = traversal().withRemote(DriverRemoteConnection.using("localhost", 8182));
g =newGraphTraversalSource(DriverRemoteConnection.using(client, 'g'))
gremlin simplest dataset example
WARN: default connection is local, need to "submit" each time
// insert data, add :submit if you did't connect to the cluster// :submit g.addV('person').....
alice=g.addV('Alice').property('sex', 'female').property('age', 30).property('name','Alice');
bob=g.addV('Bob').property('sex', 'male').property('age', 35).property('name','Bob').as("Bob");
marie=g.addV('Marie').property('sex', 'female').property('age', 5).property('name','Marie');
g.tx().commit() // only for transactional TraversalSource// select id of element
alice_id=g.V().hasLabel('Alice').id().next();
bob_id=g.V().has('name','Bob').id().next()
alice_id=g.V().has('name','Alice').id().next()
marie_id=g.V().has('name','Marie').id().next()
bob=g.V( bob_id )
alice=g.V( alice_id )
:show variables
// select vertex
g.V() \
.has("sex", "female") \
.has("age", lte(30)) \
.valueMap("age", "sex", "name")
// .values("age") // g.V().hasLabel('Bob').addE('wife').to(g.V().has('name', 'Alice'))// The child traversal of [GraphStep(vertex,[]), HasStep([name.eq(Alice)])] was not spawned anonymously - use the __ class rather than a TraversalSource to construct the child traversal
g.V(bob_id).addE('wife').to(__.V(alice_id)) \
.property("start_time", 2010).property("place", "Canada");
g.V().hasLabel('Bob').addE('daughter').to(__.V().has('name', 'Marie')) \
.property("start_time", 2013).property("birth_place", "Toronto");
g.addE('mother').to(__.V(alice_id)).from(__.V(marie_id))
// select all vertices
g.V().id()
// select all edges
g.E()
// select data: edges out of
g.V().has("name","Bob").outE()
// select data: edges in to
g.V().has("name","Alice").inE().outV().values("name")
// select data: out edge(wife), point in
g.V().has("name","Bob").outE("wife").inV().values("name")
// select data: out edge(wife), point to Vertext, in edge(mother), coming from
g.V().has("name","Bob").outE("wife").inV().inE("mother").outV().values("name")
// remove Vertex
g.V('4280').drop()
// remove Edge
g.V().has("name", "Bob").outE("wife").drop()
:exit
// export DB to GraphSON ( JSON )
g.io("/workspace/output.json").with(IO.writer, IO.graphson).write().iterate()
// import from GraphSON ( JSON ) to DB
g.io("/workspace/output.json").with(IO.reader, IO.graphson).read().iterate()
// export DB to GraphML ( XML )
g.io("/workspace/output.xml").with(IO.writer, IO.graphml).write().iterate()
// import from GraphML ( XML ) to DB
g.io("/workspace/output.xml").with(IO.reader, IO.graphml).read().iterate()
// ------------ doesn't work// import db// graph = JanusGraphFactory.open('conf/janusgraph.properties')// graph = JanusGraphFactory.open('conf/remote-graph.properties')// reader = g.graph.io(graphml()).reader().create()// inputStream = new FileInputStream('/workspace/simple-dataset.graphml')// reader.readGraph(inputStream, g.graph)// inputStream.close()
g.V()
# this path is **server path** not the local one
PATH_TO_EXPORT_JSON="/workspace/output.json"
g.io(PATH_TO_EXPORT_JSON).with_(IO.reader, IO.graphson).read().iterate()
flowchart LR
subgraph client [client side]
direction TB
ca[client application] -->|1| ced[client encoding]
ced -->|2 client| cr[gRPC Runtime]
cr -->|3| ctr[transport]
end
subgraph server [server side]
direction TB
ctr -->|4| str[transport]
str -->|5| sr[gRPC Runtime]
sr -->|6| sed[client decoding]
sed -->|7| sa[server application]
end
sa --> sed
sed --> sr
sr --> str
str --> ctr
ctr --> cr
cr --> ced
ced --> ca
namespace, meta-info, file blocks
single point of failure
single point of communication for external clients
Datanode
data block, send heartbeat to Namenode worker executed on DataNode
worker associated with slot in DataNode
Daemons
Primary Node
Secondary Node
Data Node
file workflow
graph LR
is([input
splitter])
f[[file]]
s[[split]]
rr([record
reader])
r[[record]]
kv[[key
value]]
if([input
format])
f -.read
one.-> is -.write
many
(each mapper).-> s
s -.read.-> rr -.create.-> r
r -.-> if
if -.-> kv
hadoop jar /opt/cloudera/parcels/CDH/jars/search-mr-1.0.0-cdh5.14.4-job.jar org.apache.solr.hadoop.HdfsFindTool -find hdfs:///data/ingest/ -type d -name "some-name-of-the-directory"
find files ( for cloudera only !!! )
hadoop jar /opt/cloudera/parcels/CDH/jars/search-mr-1.0.0-cdh5.14.4-job.jar org.apache.solr.hadoop.HdfsFindTool -find hdfs:///data/ingest/ -type f -name "some-name-of-the-file"
PARK_MAJOR_VERSION is set to 2, using Spark2
Error in pyspark startup:
IPYTHON and IPYTHON_OPTS are removed in Spark 2.0+. Remove these from the environment and set PYSPARK_DRIVER_PYTHON and PYSPARK_DRIVER_PYTHON_OPTS instead.
just set variable to using Spart1 inside script: SPARK_MAJOR_VERSION=1
column familty (limited number) can be configured to:
compress
versions count
TimeToLive 'veracity'
in memory/on disc
separate file
key - is byte[], value is byte[]
scan by key
scan by keys range
schema free
each record has a version
TableName - filename
record looks like: RowKey ; ColumnFamilyName ; ColumnName ; Timestamp
table can divide into number of regions (sorted be key with start...end keys and controlled by HMaster )
region has default size 256Mb
data is sparse - a lot of column has null values
fast retrieving data by 'key of the row' + 'column name'
contains from: (HBase HMaster) *---> (HBase Region Server)
checkAndPut - compares the value with the current value from the hbase according to the passed CompareOp. CompareOp=EQUALS Adds the value to the put object if expected value is equal.
checkAndMutate - compares the value with the current value from the hbase according to the passed CompareOp.CompareOp=EQUALS Adds the value to the rowmutation object if expected value is equal.
row mutation example
RowMutationsmutations = newRowMutations(row);
//add new columnsPutput = newPut(row);
put.add(cf, col1, v1);
put.add(cf, col2, v2);
Deletedelete = newDelete(row);
delete.deleteFamily(cf1, now);
//delete column family and add new columns to same familymutations.add(delete);
mutations.add(put);
table.mutateRow(mutations);
# the location of Helm's configurationecho$HELM_HOME# the host and port that Tiller is listening onecho$TILLER_HOST# the path to the helm command on your systemecho$HELM_BIN# the full path to this plugin (not shown above, but we'll see it in a moment).echo$HELM_PLUGIN_DIR
analyze local package
helm inspect { folder }
helm lint { folder }
search remote package
helm search
helm describe {full name of the package}
information about remote package
helm info {name of resource}
helm status {name of resource}
create package locally
helm create
create package with local templates
ls -la ~/.helm/starters/
install package
helm install { full name of the package }
helm install --name {my name for new package} { full name of the package }
helm install --name {my name for new package} --namespace {namespace} -f values.yml --debug --dry-run { full name of the package }
# some examples
helm install bitname/postgresql
helm install oci://registry-1.docker.io/bitnamicharts/postgresql
helm install my_own_postgresql bitname/postgresql
helm upgrade {name of package} {folder with helm scripts} --set replicas=2
check upgrade
helm history
helm rollback {name of package} {revision of history}
remove packageHelm
helm delete --purge {name of package}
trouble shooting
issue with 'helm list'
E1209 22:25:57.285192 5149 portforward.go:331] an error occurred forwarding 40679 -> 44134: error forwarding port 44134 to pod de4963c7380948763c96bdda35e44ad8299477b41b5c4958f0902eb821565b19, uid : unable to do port forwarding: socat not found.
Error: transport is closing
Database
namespace for tables separation
-> Table
unit of data inside some schema
-> Partition
virtual column ( example below )
-> Buckets
data of column can be divided into buckets based on hash value
Partition and Buckets serve to speed up queries during reading/joining
example of bucket existence
database -> $WH/testdb.db
table -> $WH/testdb.db/T
partition -> $WH/testdb.db/T/date=01012013
bucket -> $WH/testdb.db/T/date=01012013/000032_0
( only 'bucket' is a file )
databases
SHOW DATABASES;
USE DATABASE default;
-- describe
DESCRIBE DATABASE my_own_database;
DESCRIBE DATABASE EXTENDED my_own_database;
-- delete database
DROP DATABASE IF EXISTS my_own_database;
-- alter database
ALTER DATABASE my_own_database SET DBPROPERTIES(...)
managed
data stored in subdirectories of 'hive.metastore.warehouse.dir'
dropping managed table will drop all data on the disc too
external
data stored outsice 'hive.metastore.warehouse.dir'
dropping table will delete metadata only
'''
CREATE EXTERNAL TABLE ...
...
LOCATION '/my/path/to/folder'
'''
create managed table with regular expression
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^]*) ([^]*) ([^]*) (-|\\[^\\]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
)
STORED AS TEXTFILE;
create managed table with complex data
CREATE TABLE users{
id INT,
name STRING,
departments ARRAY<STRING>
} ROW FORMAT DELIMITED FIELD TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ':'
STORED AS TEXTFILE;
1, Mike, sales|manager
2, Bob, HR
3, Fred, manager| HR
4,Klava, manager|sales|developer|cleaner
create managed table with partition
CREATE TABLE users{
id INT,
name STRING,
departments ARRAY<STRING>
}
PARTITIONED BY (office_location STRING )
ROW FORMAT DELIMITED FIELD TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ':'
STORED AS TEXTFILE;
--
-- representation on HDFS
$WH/mydatabase.db/users/office_location=USA
$WH/mydatabase.db/users/office_location=GERMANY
CREATE EXTERNAL TABLE IF NOT EXISTS school_explorer(
grade boolean,
is_new boolean,
location string,
name string,
sed_code STRING,
location_code STRING,
district int,
latitude float,
longitude float,
address string
)COMMENT 'School explorer from Kaggle'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE LOCATION '/data/';
-- do not specify filename !!!!
-- ( all files into folder will be picked up )
create table from CSV format file
CREATE TABLE my_table(a string, b string, ...)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = "\t",
"quoteChar" = "'",
"escapeChar" = "\\"
)
STORED AS TEXTFILE LOCATION '/data/';
create table from 'tab' delimiter
CREATE TABLE web_log(viewTime INT, userid BIGINT, url STRING, referrer STRING, ip STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/mapr/sample-table.txt' INTO TABLE web_log;
JSON
CREATE TABLE my_table(a string, b bigint, ...)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
external Parquet
create external table parquet_table_name (x INT, y STRING)
ROW FORMAT SERDE 'parquet.hive.serde.ParquetHiveSerDe'
STORED AS
INPUTFORMAT "parquet.hive.DeprecatedParquetInputFormat"
OUTPUTFORMAT "parquet.hive.DeprecatedParquetOutputFormat"
LOCATION '/test-warehouse/tinytable';
drop table
DROP TABLE IF EXISTS users;
alter table - rename
ALTER TABLE users RENAME TO external_users;
alter table - add columns
ALTER TABLE users ADD COLUMNS{
age INT, children BOOLEAN
}
View
CREATE VIEW young_users SELECT name, age FROM users WHERE age<21;
DROP VIEW IF EXISTS young_users;
Index
create index for some specific field, will be saved into separate file
CREATE INDEX users_name ON TABLE users ( name ) AS 'users_name';
show index
SHOW INDEX ON users;
delete index
DROP INDEX users_name on users;
DML
load data into table
-- hdfs
LOAD DATA LOCAL INPATH '/home/user/my-prepared-data/' OVERWRITE INTO TABLE apachelog;
-- local file system
LOAD DATA INPATH '/data/' OVERWRITE INTO TABLE apachelog;
-- load data with partitions, override files on hdfs if they are exists ( without OVERWRITE )
LOAD DATA INPATH '/data/users/country_usa' INTO TABLE users PARTITION (office_location='USA', children='TRUE')
-- example of partition location: /user/hive/warehouse/my_database/users/office_location=USA/children=TRUE
data will be copied and saved into: /user/hive/warehouse
if cell has wrong format - will be 'null'
insert data into table using select, insert select
INSERT OVERWRITE TABLE <table destination>
-- INSERT OVERWRITE TABLE <table destination>
-- CREATE TABLE <table destination>
SELECT <field1>, <field2>, ....
FROM <table source> s JOIN <table source another> s2 ON s.key_field=s2.key_field2
-- LEFT OUTER
-- FULL OUTER
export data from Hive, data external copy, data copy
INSERT OVERWRITE LOCAL DIRECTORY '/home/users/technik/users-db-usa'
SELECT name, office_location, age
FROM users
WHERE office_location='USA'
select
SELECT * FROM users LIMIT 1000;
SELECT name, department[0], age FROM users;
SELECT name, struct_filed_example.post_code FROM users ORDER BY age DESC;
SELECT .... FROM users GROUP BY age HEAVING MIN(age)>50
-- from sub-query
FROM ( SELECT * FROM users WHERE age>30 ) custom_sub_query SELECT custom_sub_query.name, custom_sub_query.office_location WHERE children==FALSE;
functions
-- if regular expression B can be applied to A
A RLIKE B
A REGEXP B
-- split string to elements
split
-- flat map, array to separated fields - instead of one field with array will be many record with one field
explode( array field )
-- extract part of the date: year, month, day
year(timestamp field)
-- extract json object from json string
get_json_object
-- common functions with SQL-92
A LIKE B
round
ceil
substr
upper
Length
count
sum
average
Error in user YAML: (<unknown>): did not find expected '-' indicator while parsing a block collection at line 4 column 1
---
## 1. **Headless Browsers & Automation Frameworks**### **Puppeteer** (Node.js)
- Headless Chrome/Chromium automation.
- Excellent for rendering JS-heavy pages.
- [GitHub](https://github.com/puppeteer/puppeteer)### **Selenium** (Multiple languages)
- Automation for all major browsers.
- Can be run headless.
- [Website](https://www.selenium.dev/)### **Playwright** (Node.js, Python, Java, .NET)
- Multi-browser support (Chromium, WebKit, Firefox).
- Feature-rich, modern alternative to Puppeteer.
- [GitHub](https://github.com/microsoft/playwright)### **Nightmare.js** (Node.js)
- Headless automation for Electron.
- Simpler than Puppeteer/Playwright, but less maintained.
- [GitHub](https://github.com/segmentio/nightmare)### **Cypress** (JavaScript)
- Primarily for end-to-end testing, but can be used to extract rendered HTML.
- [Website](https://www.cypress.io/)Here is a list of popular **console (text-based) browsers** with the ability to dump the screen or page content:
---
2. **Console Browsers **
1. w3m
Description: Text-based web browser with support for tables, frames, SSL, and images (in terminals with graphics support).
# select data
curl --header "Authorization: Token $INFLUX_TOKEN" --header "Content-Type: application/x-www-form-urlencoded" -G "$INFLUX_URL/query?pretty=true" \
--data-urlencode "db=${INFLUX_BUCKET}" \
--data-urlencode "q=select * from foods"# "q=SELECT * FROM \"events\" WHERE \"type\"='start' and \"applicationName\"='SessionIngestJob$' limit 10"
curl -G 'http://tesla-influx.k8sstg.mueq.adas.intel.com/query?pretty=true' --data-urlencode "db=metrics" --data-urlencode "q=SELECT jobId FROM \"events\" limit 10"
delete record
curl --silent -G "https://dq-influxdb.dplapps.vantage.org:443/query?pretty=true" \
--data-urlencode "db=${INFLUX_BUCKET}" \
--data-urlencode "q=DROP SERIES FROM \"km-dr\" WHERE \"session\"='aa416-7dcc-4537-8045-83afa2' and \"vin\"='V77777'"
CREATEUSERtelegraf WITH PASSWORD 'telegrafmetrics' WITH ALL PRIVILEGES
# OpenShift settings# connect to openshift
$ oc login $OC_HOST:8443
# forward ports from localhost to pod# oc port-forward $POD_NAME <local port>:<remote port>
$ oc port-forward $POD_NAME 5006
# e.g. connect to the jmx port with visual vm
visualvm --openjmx localhost:5006
jconsole localhost:5006
# set breakpoint on line
stop at com.ubs.ad.data.interval.v2.IntervalServiceImpl:189
# set breakpoint on method
stop at com.ubs.ad.data.interval.v2.IntervalServiceImpl.getAvailability
# print list of breakpoints
clear
# remove breakpoint
clear com.ubs.ad.data.interval.v2.IntervalServiceImpl:189
# print local variables
locals
# for all methods need to use full name of the class
print com.ubs.interval.IntervalValidator.isContributorIdValid(subscriber)
eval com.ubs.interval.IntervalValidator.isContributorIdValid(subscriber)
# print current stack trace, print position
where
print intervalsIdList
dump intervalsIdList
set intervalsIdList=new ArrayList<>();
movements inside debugger
next -- step one line (step OVER calls)
cont -- continue execution from breakpoint
step -- execute current line ( step in )
step up -- execute until the current method returns to its caller
stepi -- execute current instruction
jdk with name "jdk8" should be configured: http://localhost:9090/configureTools/
maven with name "mvn-325" should be configured: http://localhost:9090/configureTools/
Could not find the Maven settings.xml config file id:paps-maven-settings. Make sure it exists on Managed Files
plugin should be present
http://localhost:9090/configfiles/
RSA key fingerprint is SHA256:xxxxxx
Are you sure you want to continue connecting (yes/no) ?
ssh://[email protected]:7999/pportal/commons.git
Topics
category of messages, consists from Partitions
Partition ( Leader and Followers )
part of the Topic, can be replicated (replication factor) across Brokers, must have at least one Leader and 0..* Followers
when you save message, it will be saved into one of the partitions depends on:
partition number | hash of the key | round robin partition size calculator
Leader
main partition in certain period of time, contains InSyncReplica's - list of Followers that are alive in current time
Committed Messages
when all InSyncReplicas wrote message, Consumer can read it after, Producer can wait for it or not
Brokers
one of the server of Kafka ( one of the server of cluster )
Producers
some process that publish message into specific topic
Consumers
topics subscriber
Consumer Group
group of consumers, have one Load Balancer for one group,
consumer instance from different group will receive own copy of message ( one message per group )
enable.auto.commit=true; # Kafka would auto commit offset at the specified interval.
# !!! do not make call to consumer.commitSync(); from the consumer. With this configuration of consumer,
auto.commit.interval.ms=1; # set it to lower timeframe
At-least-once
offset controlled by broker
scenario happens when consumer processes a message and commits the message into its persistent store and consumer crashes at that point, haven't commit to kafka broker
Duplicate message delivery could happen in the following scenario.
quarkus.kafka-streams.processing-guarantee=at_least_once
enable.auto.commit=false # enable.auto.commit=true and auto.commit.interval.ms=999999999999999
# consumer.commitSync(); # After reading. Consumer should now then take control of the message offset commits
offset controlled by consumer in external storage
quarkus.kafka-streams.processing-guarantee=exactly_once # exactly_once_v2
enable.auto.commit=false
# !!! do not make call to consumer.commitSync();
# use new KafkaConsumer<String, String>(props).subscribe("topic", ConsumerRebalancerListener)
flowchart RL
c --o cs[Consumer]
of[OffsetManager] --o c[ConsumerRebalancerListener]
of <-.->|rw| es[offset
ExternalStorage ]
SQL -->|extends| es
NoSQL -->|extends| es
Kafka[Kafka
exactly_once_v2] -->|extends| es
Loading
ZoopKeeper ( one instance per cluster )
must be started before using Kafka ( zookeeper-server-start.sh, kafka-server-start.sh )
Propertiesprops = newProperties();
props.put("bootstrap.servers", "localhost:4242");
props.put("acks", "all"); // 0 - no wait; 1 - leader write into local log; all - leader write into local log and wait ACK from full set of InSyncReplications props.put("client.id", "unique_client_id"); // nice to haveprops.put("retries", 0); // can change ordering of the message in case of retriyingprops.put("batch.size", 16384); // collect messages into batchprops.put("linger.ms", 1); // additional wait time before sending batchprops.put("compression.type", ""); // type of compression: none, gzip, snappy, lz4props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = newKafkaProducer<>(props);
producer.metrics(); // for(inti = 0; i < 100; i++)
producer.send(newProducerRecord<String, String>("mytopic", Integer.toString(i), Integer.toString(i)));
producer.flush(); // immediatelly send, even if 'linger.ms' is greater than 0producer.close();
producer.partitionsFor("mytopic")
Propertiesprops = newProperties();
props.put("bootstrap.servers", "localhost:4242"); // list of host/port pairs to connect to clusterprops.put("client.id", "unique_client_id"); // nice to haveprops.put("group.id", "unique_group_id"); // nice to haveprops.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("fetch.min.bytes", 0); // if value 1 - will be fetched immediatellyprops.put("enable.auto.commit", "true"); //// timeout of detecting failures of consumer, Kafka group coordinator will wait for heartbeat from consumer within this period of timeprops.put("session.timeout.ms", "1000");
// expected time between heartbeats to the consumer coordinator,// is consumer session stays active, // facilitate rebalancing when new consumers join/leave group,// must be set lower than *session.timeout.ms*props.put("heartbeat.interval.ms", "");
consumer java
NOT THREAD Safe !!!
KafkaConsumer<String, String> consumer = newKafkaConsumer<>(props);
ConsumerRecords<String, String> records = consumer.pool(100); // time in ms
kafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -o beginning -K\t| grep $MESSAGE_KEY# shrink time of the scan from "beginning" to something more expected
rm -rf ~/.kube/cache
kubectl get pods -v=6
kubectl get pods -v=7
kubectl get pods -v=8
# with specific context file from ~/.kube, specific config
kubectl --kubeconfig=config-rancher get pods -v=8
The user deploys a new app by using the kubectl CLI. Kubectl sends the request to the API server.
The API server receives the request and stores it in the data store (etcd). After the request is written to the data store, the API server is done with the request.
Watchers detect the resource changes and send notifications to the Controller to act on those changes.
The Controller detects the new app and creates new pods to match the desired number of instances. Any changes to the stored model will be used to create or delete pods.
The Scheduler assigns new pods to a node based on specific criteria. The Scheduler decides on whether to run pods on specific nodes in the cluster. The Scheduler modifies the model with the node information.
A Kubelet on a node detects a pod with an assignment to itself and deploys the requested containers through the container runtime, for example, Docker. Each node watches the storage to see what pods it is assigned to run. The node takes necessary actions on the resources assigned to it such as to create or delete pods.
Kubeproxy manages network traffic for the pods, including service discovery and load balancing. Kubeproxy is responsible for communication between pods that want to interact.
### Master## API Server, responsible for serving the API
/var/log/kube-apiserver.log
## Scheduler, responsible for making scheduling decisions
/var/log/kube-scheduler.log
## Controller that manages replication controllers
/var/log/kube-controller-manager.log
### Worker Nodes## Kubelet, responsible for running containers on the node
/var/log/kubelet.log
## Kube Proxy, responsible for service load balancing
/var/log/kube-proxy.log
kubernetes CLI
kubernetes version, k8s version
kubeadm version
one of the field will be like:
GitVersion:"v1.11.1"
# will fail if no `tar` in container !!!
kubectl --namespace "$KUBECONFIG_ENV" cp "$KUBECONFIG_ENV/$STREAM_POD_NAME:/deployment/app/cloud-application-kafka-streams*.jar" cloud-application-kafka-streams.jar
check namespaces
kubectl get namespaces
at least three namespaces will be provided
default Active 15m
kube-public Active 15m
kube-system Active 15m
ps aux | grep kube-apiserver
# expected output# --authorization-mode=Node,RBAC
# read existing roles
kubectl get clusterRoles
# describe roles created by permission-management
kubectl describe clusterRoles/template-namespaced-resources___developer
kubectl describe clusterRoles/template-namespaced-resources___operation
# get all rolebindings
kubectl get RoleBinding --all-namespaces
kubectl get ClusterRoleBinding --all-namespaces
kubectl get rolebindings.rbac.authorization.k8s.io --all-namespaces
# describe one of bindings
kubectl describe ClusterRoleBinding/student1___template-cluster-resources___read-only
kubectl describe rolebindings.rbac.authorization.k8s.io/student1___template-namespaced-resources___developer___students --namespace students
Direct request to api, user management curl
TOKEN="Authorization: Basic YWRtaW46b2xnYSZ2aXRhbGlp"
curl -X GET -H "$TOKEN" http://localhost:4000/api/list-users
The operator reads information from external APIs (AWS Secrets Manager, HashiCorp Vault, Google Secrets Manager...)
and automatically injects the values into a Kubernetes Secret.
get resources
kubectl get all --all-namespaces
# check pod statuses
kubectl get pods
kubectl get pods --namespace kube-system
kubectl get pods --show-labels
kubectl get pods --output=wide --selector="run=load-balancer-example"
kubectl get pods --namespace training --field-selector="status.phase==Running,status.phase!=Unknown"
kubectl get service --output=wide
kubectl get service --output=wide --selector="app=helloworld"
kubectl get deployments
kubectl get replicasets
kubectl get nodes
kubectl get cronjobs
kubectl get daemonsets
kubectl get pods,deployments,services,rs,cm,pv,pvc -n demo
kubectl list services
kubectl describe service my_service_name
determinate cluster 'hostIP' to reach out application(s)
minikube ip
open 'kube-dns-....'/hostIP
open 'kube-proxy-....'/hostIP
edit configuration of controller
kubectl edit pod hello-minikube-{some random hash}
kubectl edit deploy hello-minikube
kubectl edit ReplicationControllers helloworld-controller
kubectl set image deployment/helloworld-deployment {name of image}
rollout status
kubectl rollout status deployment/helloworld-deployment
rollout history
kubectl rollout history deployment/helloworld-deployment
kubectl rollout undo deployment/helloworld-deployment
kubectl rollout undo deployment/helloworld-deployment --to-revision={number of revision from 'history'}
delete running container
kubectl delete pod hello-minikube-6c47c66d8-td9p2
delete deployment
kubectl delete deploy hello-minikube
delete ReplicationController
kubectl delete rc helloworld-controller
delete PV/PVC
oc delete pvc/pvc-scenario-output-prod
port forwarding from local to pod/deployment/service
next receipts allow to redirect 127.0.0.1:8080 to pod:6379
ssh {node address}
# hard way: rm -rf /etc/kubernetes
kubeadm reset
# apply token from previous step with additional flag: --ignore-preflight-errors=all
kubeadm join 10.14.26.210:6443 --token 7h0dmx.2v5oe1jwed --discovery-token-ca-cert-hash sha256:1d28ebf950316b8f3fdf680af5619ea2682707f2e966fc0 --ignore-preflight-errors=all
expected result from previous command
...
This node has joined the cluster:
* Certificate signing request was sent to master and a response
was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
# remove died pods
kubectl delete pods kube-flannel-ds-amd64-zsfz --grace-period=0 --force
# delete all resources from file and ignore not found
kubectl delete -f --ignore-not-found https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl create -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
install flannel
### apply this with possible issue with installation: ## kube-flannel.yml": daemonsets.apps "kube-flannel-ds-s390x" is forbidden: User "system:node:name-of-my-server" cannot get daemonsets.apps in the namespace "kube-system"# sudo kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml## Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized# sudo kubectl -n kube-system apply -f https://raw.githubusercontent.com/coreos/flannel/bc79dd1505b0c8681ece4de4c0d86c5cd2643275/Documentation/kube-flannel.yml## print all logs
journalctl -f -u kubelet.service
# $KUBELET_NETWORK_ARGS in # /etc/systemd/system/kubelet.service.d/10-kubeadm.conf## ideal way, not working properly in most cases
sudo kubectl -n kube-system apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
## check installation
ps aux | grep flannel
# root 13046 0.4 0.0 645968 24748 ? Ssl 10:49 0:00 /opt/bin/flanneld --ip-masq --kube-subnet-mgr
ifconfig
cni0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 10.244.0.1 netmask 255.255.255.0 broadcast 0.0.0.0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
change settings and restart
kubectl edit cm kube-flannel-cfg -n kube-system
# net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } }# Wipe current CNI network interfaces remaining the old network pool:
sudo ip link del cni0; sudo ip link del flannel.1
# Re-spawn Flannel and CoreDNS pods respectively:
kubectl delete pod --selector=app=flannel -n kube-system
kubectl delete pod --selector=k8s-app=kube-dns -n kube-system
# waiting for restart of all services
# nfs server
vim /etc/exports
# /mnt/disks/k8s-local-storage/nfs 10.55.0.0/16(rw,sync,no_subtree_check)# /mnt/disks/k8s-local-storage1/nfs 10.55.0.0/16(rw,sync,no_subtree_check)
sudo exportfs -a
sudo exportfs -v
systemctl status nfs-server
ll /sys/module/nfs/parameters/
ll /sys/module/nfsd/parameters/
sudo blkid
sudo vim /etc/fstab
# UUID=35c71cfa-6ee2-414a-5555-effc30555555 /mnt/disks/k8s-local-storage ext4 defaults 0 0# UUID=42665716-1f89-44d4-5555-37b207555555 /mnt/disks/k8s-local-storage1 ext4 defaults 0 0
nfsstat
master. mount volume ( nfs server )
# create point
sudo mkdir /mnt/disks/k8s-local-storage1
# mount
sudo mount /dev/sdc /mnt/disks/k8s-local-storage1
sudo chmod 755 /mnt/disks/k8s-local-storage1
# createlink
sudo ln -s /mnt/disks/k8s-local-storage1/nfs /mnt/nfs1
ls -la /mnt/disks
ls -la /mnt
# update storage
sudo cat /etc/exports
# /mnt/disks/k8s-local-storage1/nfs 10.55.0.0/16(rw,sync,no_subtree_check)# restart
sudo exportfs -a
sudo exportfs -v
nfs client
sudo blkid
sudo mkdir /mnt/nfs1
sudo chmod 777 /mnt/nfs1
sudo vim /etc/fstab
# add record# 10.55.0.3:/mnt/disks/k8s-local-storage1/nfs /mnt/nfs1 nfs rw,noauto,x-systemd.automount,x-systemd.device-timeout=10,timeo=14 0 0
10.55.0.3:/mnt/disks/k8s-local-storage1/nfs /mnt/nfs1 nfs defaults 0 0
# refresh fstab
sudo mount -av
# for server
ls /mnt/disks/k8s-local-storage
ls /mnt/disks/k8s-local-storage1
# for clients
ls /mnt/disks/k8s-local-storage1
trouble shooting, problem resolving
POD_NAME=service-coworking-postgresql-0
kubectl get pod $POD_NAME -o json
kubectl describe pod $POD_NAME
kubectl get --watch events
kubectl get events --sort-by=.metadata.creationTimestamp
kubectl get events --field-selector type=Warning
kubectl get events --field-selector type=Error
kubectl get events --field-selector type=Critical
kubectl get pvc data-service-coworking-postgresql-0 -o json
time# run GNU version of the command:
/etc/bin/time
# or \time
retrieve human readable information from binary files
strings /usr/share/teams/libEGL.so | grep git
place for scripts, permanent script
### system wide for all users### /etc/profile is only run at login### ~/.profile file runs each time a new shell is started # System-wide .bashrc file for interactive bash(1) shells.
/etc/bash.bashrc
# system-wide .profile file for the Bourne shell sh(1)
/etc/profile
/etc/environment
/etc/profile.d/my_new_update.sh
### during user login~/.bash_profile
# executed by Bourne-compatible login shells.~/.profile
# during open the terminal, executed by bash for non-login shells.~/.bashrc
solution: scp should be installed on both!!! hosts
tunnel, port forwarding from local machine to outside
ssh -L <local_port>:<remote_host from ssh_host>:<remote_port><username>@<ssh_host># ssh -L 28010:remote_host:8010 user_name@remote_host
ssh -L <local_port>:<remote_host from ssh_host>:<remote_port><ssh_host># ssh -L 28010:vldn337:8010 localhost# destination service on the same machine as ssh_host# localport!=remote_port (28010!=8010)
ssh -L 28010:127.0.0.1:8010 user_name@remote_host
tunnel, port forwarding from outside to localmachine
# ssh -R <remoteport>:<local host name>:<local port> <hostname># localy service on port 9092 should be started# and remotelly you can reach it out just using 127.0.0.1:7777
ssh -R 7777:127.0.0.1:9092 localhost
tunnel for remote machine with proxy, local proxy for remote machine, remote proxy access
//TODO
local=======>remote
after that, remote can use local as proxy
first of all start local proxy (proxychains or redsock)
# locally proxy server on port 9999 should be started
ssh -D 9999 127.0.0.1 -t ssh -R 7777:127.0.0.1:9999 [email protected]# from remote machine you can execute
wget -e use_proxy=yes -e http_proxy=127.0.0.1:7777 https://google.com
ssh suppress banner, ssh no invitation
ssh -q my_server.org
ssh verbosive, ssh log, debug ssh
ssh -vv my_server.org
ssh variable ssh envvar ssh send variable
ssh variable in command line
ssh -t user@host VAR1="Petya" bash -l
sshd config
locally: ~/.ssh/config
SendEnv MY_LOCAL_VAR
remotely: /etc/ssh/sshd_config
AcceptEnv MY_LOCAL_VAR
ssh environment, execute on remote server bash file after login
open ports, open connections, listening ports, application by port, application port, process port, pid port
# list of open files
sudo lsof -i -P -n | grep LISTEN
# list of files for specific user
lsof -u my_own_user
# limit of files for userulimit -a
# list of open connections
sudo netstat -tulpan | grep LISTEN
sudo ss -tulwn | grep LISTEN
# list of open ports
sudo nmap -sT -O 127.0.0.1
# print pid of process that occupying 9999 port
sudo ss -tulpan 'sport = :9999'# open input output
iotop
# list of services mapping service to port mapping port to service
less /etc/services
mount drive to path mount
# <drive> <path>
sudo mount /dev/sdd /tin
mount remote filesystem via ssh, map folder via ssh, ssh remote folder
sudo mkdir /mnt/disks/k8s-local-storage1
sudo chmod 755 /mnt/disks/k8s-local-storage1
sudo ln -s /mnt/disks/k8s-local-storage1/nfs nfs1
ls -la /mnt/disks
ls -la /mnt
sudo blkid
sudo vim /etc/fstab
# add record# UUID=42665716-1f89-44d4-881c-37b207aecb71 /mnt/disks/k8s-local-storage1 ext4 defaults 0 0# refresg fstab reload
sudo mount -av
ls /mnt/disks/k8s-local-storage1
option 2
sudo vim /etc/fstab
# add line# /dev/disk/by-uuid/8765-4321 /media/usb-drive vfat 0 0# copy everything from ```mount```# /dev/sdd5 on /media/user1/e91bd98f-7a13-43ef-9dce-60d3a2f15558 type ext4 (rw,nosuid,nodev,relatime,uhelper=udisks2)# /dev/sda1 on /media/kali/usbdata type fuseblk (rw,nosuid,nodev,relatime,user_id=0,group_id=0,default_permissions,allow_other,blksize=4096,uhelper=udisks2)# systemctl daemon-reload
sudo mount -av
repeat last command with substring "flow" included into whole command line
!?flow
execute in current dir, inline shell execution
. goto-command.sh
directories into stack
pushd
popd
dirs
to previous folder
cd -
sudo reboot
shutdown -r now
sort, order
# sort for human readable
sort -h
sort -n
sort -v
# sort by column ( space delimiter )
sort -k 3 <filename># sort by column number, with delimiter, with digital value ( 01, 02....10,11 )
sort -g -k 11 -t "/" session.list
# sort with reverse order
sort -r <filename>
print file with line numbers, output linenumbers
cat -n <filename>
split and join big files split and merge, make parts from big file copy parts
substring with fixed number of chars: from 1.to(15) and 1.to(15) && 20.to(50)
cut -c1-15
cut -c1-15,20-50
output to file without echo on screen, echo without typing on screen
echo"text file"| grep "">$random_script_filename
system log information, logging
# read log
tail -f /var/log/syslog
# write to system logecho"test"| /usr/bin/logger -t cronjob
# write log message to another system
logger --server 192.168.1.10 --tcp "This is just a simple log line"
/var/log/messages
commands execution logging session logging
# write output of command to out.txt and execution time to out-timing.txt
script out.txt --timing=out-timing.txt
repository list of all repositories
sudo cat /etc/apt/sources.list*
add repository
add-apt-repository ppa:inkscape.dev/stable
you can find additional file into
/etc/apt/sources.list.d
or manually add repository
# https://packages.debian.org/bullseye/amd64/skopeo/download# The following signatures couldn't be verified because the public key is not available# deb [trusted=yes] http://ftp.at.debian.org/debian/ bullseye main contrib non-free
avoid to put command into history, hide password into history, avoid history
add space before command
history settings history ignore duplicates history datetime
HISTTIMEFORMAT="%Y-%m-%d %T "
HISTCONTROL=ignoreboth
history
bash settings, history lookup with arrows, tab autocomplete
~/.inputrc
"\e[A": history-search-backward
"\e[B": history-search-forward
set show-all-if-ambiguous on
set completion-ignore-case on
TAB: menu-complete
"\e[Z": menu-complete-backward
set show-all-if-unmodified on
set show-all-if-ambiguous on
script settings
# stop execution when non-zero exit
set -e
# stop execution when error happend even inside pipeline
set -eo pipeline
# stop when access to unknown variable
set -u
# print each command before execution
set -x
# export source export variables
set -a
source file-with-variables.env
execute command via default editor
ctrl+x+e
edit last command via editor
fc
folder into bash script
working folder
pwd
process directory process working dir
pwdx <process id>
bash reading content of the file to command-line parameter
auto execute during startup, run during restart, autoexec.bat, startup script run
cron startup run
@reboot
rc0...rc1 - runlevels of linux
ID
Name
Description
0.
Halt
Shuts down the system.
1.
Single-user Mode
Mode for administrative tasks.
2.
Multi-user Mode
Does not configure network interfaces and does not export networks services.
3.
Multi-user Mode with Networking
Starts the system normally.
4.
Not used/User-definable
For special purposes.
5.
Start the system normally with with GUI
As runlevel 3 + display manager.
6.
Reboot
Reboots the system.
one of folder: /etc/rc1.d ( rc2.d ... )
contains links to /etc/init.d/S10nameofscript ( for start and K10nameofscript for shutdown )
can understand next options: start, stop, restart
/etc/init.d/apple-keyboard
#!/bin/sh# Apple keyboard init#### BEGIN INIT INFO# Provides: cherkashyn# Required-Start: $local_fs $remote_fs# Required-Stop: $local_fs $remote_fs# Default-Start: 4 5# Default-Stop:# Short-Description: apple keyboard Fn activating### END INIT INFO# Carry out specific functions when asked to by the systemcase"$1"in
start)
echo"Starting script blah "
;;
stop)
echo"Stopping script blah"
;;
*)
echo"Usage: /etc/init.d/blah {start|stop}"exit 1
;;
esacexit 0
sudo update-rc.d apple-keyboard defaults
# sudo update-rc.d apple-keyboard remove
find /etc/rc?.d/ | grep apple | xargs ls -l
custom service, service destination
sudo vim /etc/systemd/system/YOUR_SERVICE_NAME.service
# alternative of chkconfig# alternative of sysv-rc-conf# list all services, service list
systemctl --all
systemctl list-units --type=service --all
# in case of any changes in service file
systemctl enable YOUR_SERVICE_NAME
systemctl start YOUR_SERVICE_NAME
systemctl status YOUR_SERVICE_NAME
systemctl daemon-reload YOUR_SERVICE_NAME
systemctl stop YOUR_SERVICE_NAME
reset X-server, re-start xserver, reset linux gui
ubuntu only
Ctrl-Alt-F1
sudo init 3
sudo init 5
sudo pkill X
sudo service lightdm stop
sudo service lightdm force-reload
start
sudo startx
sudo service lightdm start
xbind catch shortcuts, custom shortcuts
doesn't work with "super"/"win" button
should be activated in "startup"/service
find . -type d -name "dist"! -path "*/node_modules/*"
find function declaration, print function, show function
type <function name>
declare -f <function name>
builtin, overwrite command, rewrite command
cd()
{
# builtin going to execute not current, but genuine function
builtin cd /home/projects
}
folder size, dir size, directory size, size directory, size folder size of folder, size of directory
sudo du -shc ./*
sudo du -shc ./* | sort -rh | head -5
free space, space size, dir size, no space left
df -ha
df -hT /
du -shx /*| sort -h
# size of folder
du -sh /home
# size my sub-folders
du -mh /home
# print first 5 leaders of size-consumers# slow way: du -a /home | sort -n -r | head -n 5
sudo du -shc ./*| sort -rh | head -5
du -ch /home
# find only files with biggest size ( top 5 )
find -type f -exec du -Sh {} + | sort -rh | head -n 5
yum ( app search )
yum list {pattern}
( example: yum list python33 )
yum install {package name}
yum repolist all
yum info {package name}
yumdb info {package name}
disconnect from terminal and let command be runned
ctrl-Z
disown -a && exit
postponed execution, execute command by timer, execute command from now, timer command
for graphical applications DISPLAY must be specified
using built-in editor
at now + 5 minutes
at> DISPLAY=:0 rifle /path/to/image
^D
using inline execution
echo"DISPLAY=:0 rifle /path/to/image/task.png"| at now + 1 min
echo"DISPLAY=:0 rifle /path/to/image/task.png"| at 11:01
print all files that process is reading
strace -e open,access <command to run application>
find process by name
ps fC firefox
pgrep firefox
pid of process by name
pidof <app name>
pidof chrome
process by id
ll /proc/${process_id}# process command line
cat /proc/${process_id}/cmdline
current process id parent process id
echo $$
echo ${PPID}
process list, process tree
# process list with hierarchy
ps axjf
ps -ef --forest
ps -fauxw
# process list full command line, ps full cmd
ps -ef ww
# list of processes by user
ps -ef -u my_special_user
grep only in certain folder without recursion, grep current folder, grep in current dir
# need to set * or mask for files in folder !!!
grep -s "search_string" /path/to/folder/*
sed -n 's/^search_string//p' /path/to/folder/*# grep in current folder
grep -s "search-string"* .*
printf"# todo\n## one\n### description for one\n## two\n## three"| grep "[#]\{3\}"# printf is sensitive to --- strings### grep boundary between two numbersprintf"# todo\n## one\n### description for one\n## two\n## three"| grep "[#]\{2,3\}"printf"# todo\n## one\n### description for one\n## two\n## three"| grep --extended-regexp "[#]{3}"### grep regexp ## characters# [[:alnum:]] All letters and numbers. "[0-9a-zA-Z]"# [[:alpha:]] All letters. "[a-zA-Z]"# [[:blank:]] Spaces and tabs. [CTRL+V<TAB> ]# [[:digit:]] Digits 0 to 9. [0-9]# [[:lower:]] Lowercase letters. [a-z]# [[:punct:]] Punctuation and other characters. "[^a-zA-Z0-9]"# [[:upper:]] Uppercase letters. [A-Z]# [[:xdigit:]] Hexadecimal digits. "[0-9a-fA-F]"## quantifiers# * Zero or more matches.# ? Zero or one match.# + One or more matches.# {n} n matches.# {n,} n or more matches.# {,m} Up to m matches.# {n,m} From n up to m matches.
du -ah .| sort -r | grep -E "^[0-9]{2,}M"
replace text in all files of current directory, replace inline, replace inplace, inline replace, sed inplace
sed --in-place 's/LinkedIn/Yahoo/g'*# replace tab symbol with comma symbol
sed --in-place 's/\t/,/g' one_file.txt
# in case of error like: couldn't edit ... not a regular file
grep -l -r "LinkedIn"| xargs sed --in-place s/LinkedIn/Yahoo/g
# sed for folder sed directory sed for files
find . -type f -exec sed -i 's/import com.fasterxml.jackson.module.scala.DefaultScalaModule;//p' {} +
no editor replacement, no vi no vim no nano, add line without editor, edit property without editor
# going to add new line in property file without editor
sed --in-place 's/\[General\]/\[General\]\nenable_trusted_host_check=0/g' matomo-php.ini
timezone
timedatectl | grep "Time zone"
cat /etc/timezone
date formatting, datetime formatting, timestamp file, file with timestamp
# print current date
date +%H:%M:%S:%s
# print date with timestamp
date -d @1552208500 +"%Y%m%dT%H%M%S"
date +%Y-%m-%d-%H:%M:%S:%s
# output file with currenttime file with currenttimestamp
python3 /imap-message-reader.py > message_reader`date +%H:%M:%S`.txt
timestamp to T-date
functiontimestamp2date(){
date -d @$(($1/1000000000)) +"%Y%m%dT%H%M%S"
}
timestamp2date 1649162083168929800
generate random string
openssl rand -hex 30
# or
urandom | tr -dc 'a-zA-Z0-9'| fold -w 8 | tr '[:upper:]''[:lower:]'| head -n 1
sudo apt install p7zip-full
7za l archive.7z
7za x archive.7z
tar archiving tar compression
# tar create
tar -cf jdk.tar 8.0.265.j9-adpt
# tar compression
tar -czvf jdk.tar.gz 8.0.265.j9-adpt
untar
# tar list of files inside
tar -tf jdk.tar
# tar extract untar
tar -xvf jdk.tar -C /tmp/jdk
# extract into destination with removing first two folders
tar -xvf jdk.tar -C /tmp/jdk --strip-components=2
# extract from URL untar from url
wget -qO- https://nodejs.org/dist/v10.16.3/node-v10.16.3-linux-x64.tar.xz | tar xvz - -C /target/directory
pipeline chain 'to file'
echo "hello from someone" | tee --append out.txt
echo "hello from someone" | tee --append out.txt > /dev/null
execute command with environment variable, new environment variable for command
ONE="this is a test";echo$ONE
activate environment variables from file, env file, export env, export all env, all variable from file, all var export, env var file
FILE_WITH_VAR=.env.local
source$FILE_WITH_VARexport$(cut -d= -f1 $FILE_WITH_VAR)# if you have comments in filesource$FILE_WITH_VARexport`cat $FILE_WITH_VAR| awk -F= '{if($1 !~ "#"){print $1}}'`
apt mark hold kubeadm
# install: this package is marked for installation.# deinstall (remove): this package is marked for removal.# purge: this package, and all its configuration files, are marked for removal.# hold: this package cannot be installed, upgraded, removed, or purged.# unhold: # auto: auto installed# manual: manually installed
Debian update package
sudo apt-get install --only-upgrade {packagename}
Debian list of packages
sudo apt list
sudo dpkg -l
First letter
desired package state ("selection state")
u
unknown
i
install
r
remove/deinstall
p
purge (remove including config files)
h
hold
Second letter
current package state
n
not-installed
i
installed
c
config-files (only the config files are installed)
U
unpacked
F
half-configured (configuration failed for some reason)
h
half-installed (installation failed for some reason)
W
triggers-awaited (package is waiting for a trigger from another package)
t
triggers-pending (package has been triggered)
Third letter
error state (you normally shouldn't see a third letter, but a space, instead)
# curl with inline data curl here document curl port document here pipe
json_mappings=`cat some_file.json`
response=`curl -X POST $SOME_HOST -H 'Content-Type: application/json' \-d @- <<EOF{ "mappings": $json_mappings, "settings" : { "index" : { "number_of_shards" : 1, "number_of_replicas" : 0 } }}EOF`echo$response
# POST request GET style
curl -X POST "http://localhost:8888/api/v1/notification/subscribe?email=one%40mail.ru&country=2&state=517&city=qWkbs&articles=true&questions=true&listings=true" -H "accept: application/json"
curl escape, curl special symbols
# https://kb.objectrocket.com/elasticsearch/elasticsearch-cheatsheet-of-the-most-important-curl-requests-252
curl -X GET "https://elasticsearch-label-search-prod.vantage.org/autolabel/_search?size=100&q=moto:*&pretty"
curl --verbose --insecure -s -X GET http://google.com
curl cookie, curl header cookie
chrome extension cookies.txt
# send predefined cookie to url
curl -b path-to-cookie-file.txt -X GET url.com
# send cookie from command line
curl --cookie "first_cookie=123;second_cookie=456;third_cookie=789" -X GET url.com
# send cookie from command line
curl 'http://localhost:8000/members/json-api/auth/user' -H 'Cookie: PHPSESSID=5c5dddcd96b9f2f41c2d2f87e799feac'# collect cookie from remote url and save in file
curl -c cookie-from-url-com.txt -X GET url.com
jq is not working properly with "-" character in property name !!!
jq is not working sometimes with "jq any properties", need to split them to two commands
nmcli con show # select target network
nmcli con show 'target-network'## disable/diactivate ivp6# nmcli con modify 'target-network' ipv6.method disabled# nmcli con modify 'target-network' ipv6.method ignore# sudo sysctl -w net.ipv6.conf.all.disable_ipv6=1## enable/activate ivp6
nmcli con show 'target-network'
nmcli con modify 'target-network' ipv6.method auto
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=0
nmcli con show 'target-network'| grep ipv6.method
## apply settings
sudo systemctl restart NetworkManager
debug network collaboration, ip packages
example with reading redis collaboration ( package sniffer )
sudo ngrep -W byline -d docker0 -t '''port 6379'
debug connection, print collaboration with remote service, sniffer
# 1------------ 2-------------------- 3--------------
sudo tcpdump -nvX -v src port 6443 and src host 10.140.26.10 and dst port not 22
# and, or, not
keystore TrustStore
TrustStore holds the certificates of external systems that you trust.
So a TrustStore is a KeyStore file, that contains the public keys/certificate of external hosts that you trust.
## list of certificates inside truststore
keytool -list -v -keystore ./src/main/resources/com/ubs/crm/data/api/rest/server/keystore_server
# maybe will ask for a password## generating ssl key stores
keytool -genkeypair -keystore -keystore ./src/main/resources/com/ubs/crm/data/api/rest/server/keystore_server -alias serverKey -dname "CN=localhost, OU=AD, O=UBS AG, L=Zurich, ST=Bavaria, C=DE" -keyalg RSA
# enter password...## Importing ( updating, adding ) trusted SSL certificates
keytool -import -file ~/Downloads/certificate.crt -keystore ./src/main/resources/com/ubs/crm/data/api/rest/server/keystore_server -alias my-magic-number
in other words, rsa certificate rsa from url x509 url:
Download the certificate by opening the url in the browser and downloading it there manually.
Run the following command: keytool -import -file <name-of-downloaded-certificate>.crt -alias <alias for exported file> -keystore myTrustStore
DNS
# check
sudo resolvectl status | grep "DNS Servers"
systemd-resolve --status
systemctl status systemd-resolved
# restart
sudo systemctl restart systemd-resolved
# current dns
sudo cat /etc/resolv.conf
# resolving hostname
dig google.com
aws example, where 10.0.0.2 AWS DNS internal server
sudo vim /etc/resolv.conf
sudo snap set system proxy.http="http://user:[email protected]:8080"
sudo snap set system proxy.https="http://user:[email protected]:8080"
export proxy_http="http://user:[email protected]:8080"
export proxy_https="http://user:[email protected]:8080"
sudo snap search visual
users/group
add user into special group, add user to group
adduser {username} {destination group name}
edit file /etc/group
add :{username} to the end of line with {groupname}:x:999
create/add user, create user with admin rights
sudo useradd test
sudo useradd --create-home test --groups sudo
# set password for new user
sudo passwd test
# set default bash shell
chsh --shell /bin/bash tecmint
sudo for user, user sudo, temporary provide sudo
sudo adduser vitalii sudo
# close all opened sessions
# after your work done
sudo deluser vitalii sudo
admin rights for script, sudo rights for script, execute as root
sudo -E bash -c 'python3'
remove user
sudo userdel -r test
create group, assign user to group, user check group, user group user roles hadoop
sudo groupadd new_group
usermod --append --groups new_group my_user
id my_user
create folder for group, assign group to folder
chgrp new_group /path/to/folder
execute sudo with current env variables, sudo env var, sudo with proxy
sudo -E <command>
execute script with current env variables send to script
mapping list
for using in VisualCode like environment: GTK_IM_MODULE="xim" code $*
content of $HOME/.config/xmodmap-hjkl
keycode 66 = Mode_switch
keysym h = h H Left
keysym l = l L Right
keysym k = k K Up
keysym j = j J Down
keysym u = u U Home
keysym m = m M End
keysym y = y Y BackSpace
keysym n = n N Delete
execute re-mapping, permanent solution
# vim /etc/profile
xmodmap $HOME/.config/xmodmap-hjkl
remap reset, reset xmodmap
setxkbmap -option
move mouse, control X server
apt-get install xdotool
# move the mouse x y
xdotool mousemove 1800 500
# left click
xdotool click 1
pls, check that you are using Xorg and not Wayland (Window system):
# !!! important !!! will produce line with suffix "\n"
base64 cAdvisor-start.sh | base64 --decode
echo"just a text string"| base64 | base64 --decode
# !!! important !!! will produce line WITHOUT suffix "\n" echo -n "just a text string "| base64
printf"just a text string "| base64
hardware serial numbers, hardware id, hardware version, system info
sudo dmidecode --string system-serial-number
sudo dmidecode --string processor-family
sudo dmidecode --string system-manufacturer
# disk serial number
sudo lshw -class disk
equipment system devices
inxi -C
inxi --memory
inxi -CfxCa
images
convert image like png or gif or jpeg... to jpg, transform image from one format to another
# list of all fonts: `fc-list`# transparent background: xc:none
convert -size 800x600 xc:white -font "Garuda" -pointsize 20 -fill black -annotate +50+50 "some text\n and more \n lines"$OUTPUT_FILE
insert image into another image, image composition
# -dPDFSETTINGS=/screen — Low quality and small size at 72dpi.# -dPDFSETTINGS=/ebook — Slightly better quality but also a larger file size at 150dpi.# -dPDFSETTINGS=/prepress — High quality and large size at 300 dpi.# -dPDFSETTINGS=/default — System chooses the best output, which can create larger PDF files.
gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/ebook -dNOPAUSE -dQUIET -dBATCH -sOutputFile=output.pdf input.pdf
doc to pdf, convert to pdf
libreoffice --headless --convert-to pdf "/home/path/Dativ.doc" --outdir /tmp/output
pdf to text, extract text from pdf, convert pdf to text
/etc/cups/cupsd.conf and changed the AuthType to None and commented the Require user @SYSTEM:
<Limit CUPS-Add-Modify-Printer CUPS-Delete-Printer CUPS-Add-Modify-Class CUPS-Delete-Class CUPS-Set-Default CUPS-Get-Devices>
AuthType None
# AuthType Default
# Require user @SYSTEM
Order deny,allow
</Limit>
and restart the service
sudo service cups restart
default printer
# show all printer drivers in system
lpinfo -m
# print all printer names
lpstat -l -v
# device for Brother_HL_L8260CDW_series: implicitclass://Brother_HL_L8260CDW_series/# set default printer
PRINTER_NAME=Brother_HL_L8260CDW_series
sudo lpadmin -d $PRINTER_NAME
# list of all hard drives, disk list
sudo lshw -class disk -short
# write image
sudo dd bs=4M if=/home/my-user/Downloads/archlinux-2019.07.01-x86_64.iso of=/dev/sdb status=progress && sync
startup/bootable usb with persistence, create usb live with persistence, usb persistence, stick persistence
for parallel disk solution Parrot is highly recommended ( good bootloader )
## more or less
sudo apt install libttspico-utils
pico2wave -w output.wav "this is text-to-speech conversion"; rifle output.wav
# too metallic
sudo apt install espeak
espeak -w output.wav "Just a text"## also too metallic
sudo apt install festival
echo"This is text saved as audio."| text2wave -o output.wav; rifle output.wav
calculator arithmethic operations add sub div multiply evaluation
>pkg-config --cflags -- devmapper
Package devmapper was not found in the pkg-config search path.
Perhaps you should add the directory containing `devmapper.pc'to the PKG_CONFIG_PATH environment variableNo package 'devmapper' found
sudo prime select query
# should be nvidia
sudo ubuntu-drivers devices
# sudo ubuntu-drivers autoinstall - don't use it
sudo apt install nvidia driver-455
# or 390, 415, .... and restart
apple keyboard, alternative
echo'options hid_apple fnmode=2 iso_layout=0 swap_opt_cmd=0'| sudo tee /etc/modprobe.d/hid_apple.conf
sudo update-initramfs -u -k all
clear
daemonize
Super+j start,cursorzoom 400 400
Escape end
shift+j cut-left
shift+k cut-down
shift+i cut-up
shift+l cut-right
j move-left
k move-down
i move-up
l move-right
space warp,click 1,end
Return warp,click 1,end
1 click 1
2 click 2
3 click 3
w windowzoom
c cursorzoom 400 400
a history-back
Left move-left 10
Down move-down 10
Up move-up 10
Right move-right 10
Touch screen
calibration
tool installation
sudo apt install xinput-calibrator
configuration
xinput_calibration
list of all devices, device list, list of devices
xinput --list
cat /proc/bus/input/devices
permanent applying
vi /usr/share/X11/xorg.conf.d/80-touch.conf
disable device
xinput --disable {number from command --list}
Keyboard Lenovo
middle button
# check input source - use name(s) for next command
xinput
# create file and add content
sudo vim /usr/share/X11/xorg.conf.d/50-thinkpad.conf
gsettings list-schemas
gsettings list-keys org.gnome.desktop.wm.keybindings
gsettings get org.gnome.desktop.wm.keybindings close
gsettings set org.gnome.desktop.wm.keybindings close "['<Super>w']"
find shortcuts in the settings
## for suppressing Super + P
gsettings list-recursively | grep "<Super>p"# UI tool: dconf-editor
gsettings set org.gnome.mutter.keybindings switch-monitor "['XF86Display']"
gsettings set org.gnome.mutter.keybindings switch-monitor "['']"
gsettings reset org.gnome.mutter.keybindings switch-monitor
raise InitError("Failed to unlock the collection!")
# kill all "keyring-daemon" sessions# clean up all previous runs
rm ~/.local/share/keyrings/*
ls -la ~/.local/share/keyrings/
dbus-run-session -- bash
gnome-keyring-daemon --unlock
# type your password, <enter> <Ctrl-D>
keyring set cc.user cherkavi
keyring get cc.user cherkavi
keyring reset password
PATH_TO_KEYRING_STORAGE=~/.local/share/keyrings/login.keyring
mv $PATH_TO_KEYRING_STORAGE"${PATH_TO_KEYRING_STORAGE}-original"# go to applications->passwords and keys-> "menu:back" -> "menu:passwords"
# vnc server
sudo apt install tigervnc-standalone-server
# tigervncserver## issue on Ubuntu 22.04# sudo apt install tightvncserver# tightvncserver# vncserver -passwordfile ~/.vnc/passwd -rfbport 5900 -display :0
vncserver
# for changing password
vncpasswd
# list of vnc servers
vncserver -list
# stop vnc server
vncserver -kill :1
# configuration
vim ~/.vnc/xstartup
# xrdb $HOME/.Xresources# startxfce4 &
vnc server with connecting to existing X session
# https://github.com/sebestyenistvan/runvncserver
sudo apt install tigervnc-scraping-server
## password for VNC server
vncpasswd
## start vnc server
X0tigervnc -PasswordFile ~/.vnc/passwd
# the same as: `x0vncserver -display :0`
x0vncserver -passwordfile ~/.vnc/passwd -rfbport 5900 -display :0
## list of the servers
x0vncserver -list
## log files
ls $HOME/.vnc/*.log
x0vncserver -kill :1
vnc start, x11vnc start, connect to existing display, vnc for existing display
# export DISPLAY=:0# Xvfb $DISPLAY -screen 0 1920x1080x16 &# Xvfb $DISPLAY -screen 0 1920x1080x24 # not more that 24 bit for color# startxfce4 --display=$DISPLAY &# sleep 1
x11vnc -quiet -localhost -viewonly -nopw -bg -noxdamage -display $DISPLAY&# just show current desktop
x11vnc
vnc commands
# start server
vncserver -geometry 1920x1080
# full command, $DISPLAY can be ommited in favoud to use "next free screen"
vncserver $DISPLAY -rfbport 5903 -desktop X -auth /home/qqtavt1/.Xauthority -geometry 1920x1080 -depth 24 -rfbwait 120000 -rfbauth /home/qqtavt1/.vnc/passwd -fp /usr/share/fonts/X11/misc,/usr/share/fonts/X11/Type1 -co /etc/X11/rgb
## Couldn't start Xtightvnc; trying default font path.## Please set correct fontPath in the vncserver script.## Couldn't start Xtightvnc process.# start server with new monitor
vncserver -geometry 1920x1080 -fp "/usr/share/fonts/X11/misc,/usr/share/fonts/X11/Type1,built-ins"# check started
ps aux | grep vnc
# kill server
vncserver -kill :1
vnc client, vnc viewer, vnc player
# !!! don't use Remmina !!!
sudo apt install xvnc4viewer
timer, terminal timer, console timer
sudo apt install sox libsox-fmt-mp3
https://github.com/rlue/timer
sudo curl -o /usr/bin/timer https://raw.githubusercontent.com/rlue/timer/master/bin/timer
sudo chmod +x /usr/bin/timer
# set timer for 5 min
timer 5
| mailto: |to set the recipient, or recipients, separate with comma |
| &cc= |to set the CC recipient(s) |
| &bcc= |to set the BCC recipient(s) |
| &subject=|to set the email subject, URL encode for longer sentences, so replace spaces with %20, etc. |
| &body= |to set the body of the message, you can add entire sentences here, including line breaks. Line breaks should be converted to %0A.|
mail console client
aerc
## create application password: https://myaccount.google.com/u/1/apppasswords## vim ~/.config/aerc/accounts.conf## vim ~/.config/aerc/aerc.conf# [filters]# text/html = "w3m -T text/html"
sudo apt install aerc
graph
m[<b>model</b>]
t[training]
i[inference]
t --associate--> m
i --associate--> m
r[regression
model]
c[classification
model]
c --extend--> m
r --extend--> m
l[label]
l --assign
to -->m
id[input data]
f[feature]
f --o id
idl[ <b>input data</b>
labeled
for training]
idnl[<b>input data</b>
not labeled
for prediction]
idl --extend--> id
idnl --extend--> id
l --o idl
id ~~~ i
Loading
Necessary knowledges
graph LR;
d[design] --> md[model <br>development] --> o[operations]
md --> d
o --> md
## volume create
VOLUME_NAME=test_volume
VOLUME_PATH=/store/processed/test_creation
mkdir $VOLUME_PATH
maprcli volume create -name $VOLUME_NAME -path $VOLUME_PATH## possible issue:# Successfully created volume: 'test_volume'# ERROR (10003) - Volume mount for /store/processed/test_creation failed, No such file or directory
public class RebalanceListener implements ConsumerRebalanceListener{
onPartitionAssigned(Collection<TopicPartition> partitions)
onPartitionRevoked(Collection<TopicPartition> partitions)
}
maprlogin print -ticketfile <your ticketfile>
# you will see expiration date like
# on 07.05.2019 13:56:47 created = 'Tue Apr 23 13:56:47 UTC 2019', expires = 'Tue May 07 13:56:47 UTC 2019'
maprcli table info -path /vantage/deploy/data-access-video/images -json
# !!! totalrows: Estimated number of rows in a table. Values may not match the actual number of rows. This variance occurs because the counter, for performance reasons, is not updated on each row.# one of the fastest option - drill request: select count(*) from dfs.`/vantage/deploy/data-access-video/images`# list of regions for table
maprcli table region list -path /vantage/deploy/data-access-video/images -json
maprdb copy table backup table
mapr copytable -src {path to source} -dst {path to destination}
# without yarn involvement
mapr copytable -src {path to source} -dst {path to destination} -mapreduce false# move table can be fulfilled with:
hadoop fs -mv
# output to file stdout
mapr dbshell 'find /mapr/prod/vantage/orchestration/tables/metadata --fields _id --limit 5 --pretty'> out.txt
mapr dbshell 'find /mapr/prod/vantage/orchestration/tables/metadata --fields _id,sessionId --where {"$eq":{"sessionId":"test-001"}} --limit 1'# request inside shell
mapr dbshell
## more prefered way of searching:
find /mapr/prod/vantage/orchestration/tables/metadata --query '{"$select":["mdf4Path.name","mdf4Path.fullPath"],"$limit":2}'
find /mapr/prod/vantage/orchestration/tables/metadata --query {"$select":["fullPath"],"$where":{"$lt":{"startTime":0}}} --pretty
find /mapr/prod/vantage/orchestration/tables/metadata --c {"$eq":{"session_id":"9aaa13577-ad80"}} --pretty
## fix issue with multiple document in output# sed 's/^}$/},/g' $file_src > $file_dest## less prefered way of searching: # last records, default sort: ASC
find /mapr/prod/vantage/orchestration/tables/metadata --fields _id --orderby loggerStartTime.utcNanos:DESC --limit 5
# amount of records: `maprcli table info -path /mapr/prod/vantage/orchestration/tables/metadata -json | grep totalrows`
find /mapr/prod/vantage/orchestration/tables/metadata --fields mdf4Path.name,mdf4Path.fullPath --limit 2 --offset 2 --where {"$eq":{"session_id":"9aaa13577-ad80"}} --orderby created_time
# array in output and in condition
find /mapr/prod/vantage/orchestration/tables/metadata --fields documentId,object_types[].id --where {"$eq":{"object_types[].id":"44447f6d853dd"}}'find /mapr/prod/vantage/orchestration/tables/metadata --fields documentId,object_types[].id --where {"$between":{"created_time":[159421119000000000,1595200100000000000]}} --limit 5
!!! important !!!, id only, no data in output but "_id": if you don't see all fields in the output, try to change user ( you don't have enough rights )
WEB_HDFS=https://ubssp000007:14000
PATH_TO_FILE="tmp/1.txt"# BASE_DIR=/mapr/dc.stg.zurich
vim ${BASE_DIR}/$PATH_TO_FILE
MAPR_USER=$USER_API_USER
MAPR_PASS=$USER_API_PASSWORD# read file
curl -X GET "${WEB_HDFS}/webhdfs/v1/${PATH_TO_FILE}?op=open" -k -u ${MAPR_USER}:${MAPR_PASS}# create folder
PATH_TO_NEW_FOLDER=tmp/example
curl -X PUT "${WEB_HDFS}/webhdfs/v1/${PATH_TO_NEW_FOLDER}?op=mkdirs" -k -u ${MAPR_USER}:${MAPR_PASS}
Mapr Hadoop run command on behalf of another user
TICKET_FILE=prod.maprticket
maprlogin renew -ticketfile $TICKET_FILE
# https://github.com/cherkavi/java-code-example/tree/master/console/java-bash-run
hadoop jar java-bash-run-1.0.jar utility.Main ls -la .
issues
with test execution ( scala, java )
Can not find IP for host: maprdemo.mapr.io
solution
# hard way
rm -rf /opt/mapr
# soft way
vim /opt/mapr/conf/mapr-clusters.conf
common issue
Caused by: javax.security.auth.login.LoginException: Unable to obtain MapR credentials
at com.mapr.security.maprsasl.MaprSecurityLoginModule.login(MaprSecurityLoginModule.java:228)
## try just to connect to db
mysql --host=mysql-dev-eu.a.db.ondigitalocean.com --port=3060 --user=admin --password=my_passw --database=masterdb
## docker mysql client
docker run -it mariadb mysql --host=mysql-dev-eu.a.db.ondigitalocean.com --port=3060 --user=admin --database=masterdb --password=my_passw
## enable server logging !!!### server-id = 1### log_bin = /var/log/mysql/mysql-bin.log
sudo sed -i '/server-id/s/^#//g' /etc/mysql/mysql.conf.d/mysqld.cnf && sudo sed -i '/log_bin/s/^#//g' /etc/mysql/mysql.conf.d/mysqld.cnf
If you can shut down the MySQL server,
you can make a physical backup that consists of all files used by InnoDB to manage its tables.
Use the following procedure:
Perform a slow shutdown of the MySQL server and make sure that it stops without errors.
Copy all InnoDB data files (ibdata files and .ibd files)
Copy all InnoDB log files (ib_logfile files)
Copy your my.cnf configuration file
backup issue: during backup strange message appears: "Enter password:" even with password in command line
mysql -h hostname -u user database < path/to/test.sql
via docker
docker run -it --volume $(pwd):/work mariadb mysql --host=eu-do-user.ondigitalocean.com --user=admin --port=25060 --database=master_db --password=pass
# docker exec --volume $(pwd):/work -it mariadbsource /work/zip-code-us.sql
show databases and switch to one of them:
show databases;
use {databasename};
user <-> role
users
show grants;
SELECT host, user FROMmysql.userwhere user='www_admin'
grant access
GRANT ALL PRIVILEGES ON`www\_masterdb`.* TO `www_admin`@`%`;
print all tables
show tables;
print all tables and all columns
select table_name, column_name, data_type frominformation_schema.columnswhere TABLE_NAME like'some_prefix%'order by TABLE_NAME, ORDINAL_POSITION
print all columns in table, show table structure
describe table_name;
show columns from table_name;
select*frominformation_schema.columnswhere TABLE_NAME='listings_dir'and COLUMN_NAME like'%PRODUCT%';
mycli mysql://user:passw@host:port/schema --execute "select table_name, column_name, data_type from information_schema.columns where TABLE_NAME like 'hlm%' order by TABLE_NAME, ORDINAL_POSITION;"| awk -F '\t''{print $1","$2","$3}'> columns
add column
-- pay attention to quotas around namesALTERTABLE`some_table` ADD `json_source`varchar(32) NOT NULL DEFAULT '';
-- don't use 'ALTER COLUMN'ALTERTABLE`some_table` MODIFY `json_source`varchar(32) NULL;
rename column
alter table messages rename column sent_time to sent_email_time;
DROPDATABASE IF EXISTS {databasename};
CREATE DATABASE {databasename}
CHARACTER SET='utf8'
COLLATE ='utf8_general_ci';
-- 'utf8_general_ci' - case insensitive-- 'utf8_general_cs' - case sensitive
create table, autoincrement
createtableIF NOT EXISTS `hlm_auth_ext`(
`auth_ext_id`bigintNOT NULL AUTO_INCREMENT PRIMARY KEY,
`uuid`varchar(64) NOT NULL,
) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8;
create column if not exists
ALTER TABLE test ADD COLUMN IF NOT EXISTS column_a VARCHAR(255);
subquery returns more than one row, collect comma delimiter, join columns in one group columns
selectu.name_f,
u.name_l,
(select GROUP_CONCAT(pp.title, '')
from hlm_practices pp where user_id=100
)
from hlm_user u
whereu.user_id=100;
date diff, compare date, datetime substraction
----- return another date with shifting by interval-- (now() - interval 1 day)----- return amount of days between two dates-- datediff(now(), datetime_field_in_db )
value substitution string replace
select (case when unsubscribed>0 then 'true' else 'false' end) from lm_user limit5;
check data
-- check urlSELECT url FROM licenses WHERE length(url)>0and url NOT REGEXP '^http*';
-- check encodingSELECT subject FROM mails WHERE subject <>CONVERT(subject USING ASCII);
-- check email addressSELECT email FROM mails WHERE length(email)>0andupper(email) NOT REGEXP '^[a-zA-Z0-9+_.-]+@[a-zA-Z0-9.-]+$';
Search
simple search
case search, case sensitive, case insensitive
-- case insensitive searchANDq.summaryLIKE'%my_criteria%'-- case sensitive ( if at least one operand is binary string )ANDq.summaryLIKE BINARY '%my_criteria%'
similar search
sounds like
selectcount(*) from users where soundex(name_first) = soundex('vitali');
selectcount(*) from listing where soundex(description) like concat('%', soundex('asylum'),'%');
full text fuzzy search
search match
SELECT pages.*,
MATCH (head, body) AGAINST ('some words') AS relevance,
MATCH (head) AGAINST ('some words') AS title_relevance
FROM pages
WHERE MATCH (head, body) AGAINST ('some words')
ORDER BY title_relevance DESC, relevance DESC
custom function, UDF
DROPFUNCTION if exists `digits_only`;
DELIMITER $$
CREATEFUNCTION `digits_only`(in_string VARCHAR(100) CHARACTER SET utf8)
RETURNS VARCHAR(100)
NO SQL
BEGIN
DECLARE ctrNumber VARCHAR(50);
DECLARE finNumber VARCHAR(50) DEFAULT '';
DECLARE sChar VARCHAR(1);
DECLARE inti INTEGER DEFAULT 1;
-- swallow all exceptions, continue in any exception
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
END;
IF LENGTH(in_string) >0 THEN
WHILE(inti <= LENGTH(in_string)) DO
SET sChar =SUBSTRING(in_string, inti, 1);
SET ctrNumber = FIND_IN_SET(sChar, '0,1,2,3,4,5,6,7,8,9');
IF ctrNumber >0 THEN
SET finNumber = CONCAT(finNumber, sChar);
END IF;
SET inti = inti +1;
END WHILE;
IF LENGTH(finNumber) >0 THEN
RETURN finNumber;
ELSE
RETURN NULL;
END IF;
ELSE
RETURN NULL;
END IF;
END$$
DELIMITER ;
issues
insert datetime issue
-- `date_start_orig` datetime NOT NULL,
(1292, "Incorrect datetime value: '0000-00-00 00:00:00' for column 'date_start_orig' at row 1")
to cure it:
'1970-01-02 00:00:00'-- or SET SQL_MODE='ALLOW_INVALID_DATES';
for removing Warning about differences in configuration and real host running:
docker exec -it apache_app_1 /bin/bash
sed --in-place 's/\[General\]/\[General\]\nenable_trusted_host_check=0/g' /var/www/html/config/config.ini.php
debug messages during request:
# request to remote resource
x-www-browser http://127.0.0.1:8080/matomo.php?idsite=3&rec=1
# create property block
sed --in-place 's/\[TagManager\]/\[TagManager\]\n\n\[Tracker\]\ndebug=1/g' /var/www/html/config/config.ini.php
# deactivate element in the block
sed --in-place 's/debug = 1/debug = 0/g' /var/www/html/config/config.ini.php
# activate element in the block
sed --in-place 's/debug = 0/debug = 1/g' /var/www/html/config/config.ini.php
In Chrome will not work due default DNT
http://127.0.0.1:8080/matomo.php?idsite=4&rec=1
# Settings->Privacy->Users opt-out->Support Do Not Track preference-> Disable ( not recommended )
select*from matomo_log_visit -- contains one entry per visit (returning visitor)select*from matomo_log_action -- contains all the type of actions possible on the website (e.g. unique URLs, page titles, download URLs…)select*from matomo_log_link_visit_action -- contains one entry per action of a visitor (page view, …)select*from matomo_log_conversion -- contains conversions (actions that match goals) that happen during a visitselect*from matomo_log_conversion_item -- contains e-commerce conversion items
client example ( head only )
<head><title>matomo-test</title><!-- Matomo --><scripttype="text/javascript">var_paq=window._paq||[];/* tracker methods like "setCustomDimension" should be called before "trackPageView" */_paq.push(["setDoNotTrack",false]);</script><!-- End Matomo Code --><!-- Matomo Tag Manager --><scripttype="text/javascript">var_mtm=_mtm||[];_mtm.push({'mtm.startTime': (newDate().getTime()),'event': 'mtm.Start'});vard=document,g=d.createElement('script'),s=d.getElementsByTagName('script')[0];g.type='text/javascript';g.async=true;g.defer=true;g.src='http://localhost:8080/js/container_1uvttUpc.js';s.parentNode.insertBefore(g,s);</script><!-- End Matomo Tag Manager --></head>
select*from matomo_log_visit -- contains one entry per visit (returning visitor)select*from matomo_log_action -- contains all the type of actions possible on the website (e.g. unique URLs, page titles, download URLs…)select*from matomo_log_link_visit_action -- contains one entry per action of a visitor (page view, …)select*from matomo_log_conversion -- contains conversions (actions that match goals) that happen during a visitselect*from matomo_log_conversion_item -- contains e-commerce conversion items
build-helper:add-test-source Add test source directories to the POM.
build-helper:add-resource Add more resource directories to the POM.
build-helper:add-test-resource Add test resource directories to the POM.
build-helper:attach-artifact Attach additional artifacts to be installed and deployed.
build-helper:maven-version Set a property containing the current version of maven.
build-helper:regex-property Sets a property by applying a regex replacement rule to a supplied value.
build-helper:regex-properties Sets a property by applying a regex replacement rule to a supplied value.
build-helper:released-version Resolve the latest released version of this project.
build-helper:parse-version Parse the version into different properties.
build-helper:remove-project-artifact Remove project's artifacts from local repository.
build-helper:reserve-network-port Reserve a list of random and unused network ports.
build-helper:local-ip Retrieve current host IP address.
build-helper:hostname Retrieve current hostname.
build-helper:cpu-count Retrieve number of available CPU.
build-helper:timestamp-property Sets a property based on the current date and time.
build-helper:uptodate-property Sets a property according to whether a file set's outputs are up to date with respect to its inputs.
build-helper:uptodate-properties Sets multiple properties according to whether multiple file sets' outputs are up to date with respect to their inputs.
build-helper:rootlocation Sets a property which defines the root folder of a multi module build.
protobuf:compile compiles main .proto definitions into Java files and attaches the generated Java sources to the project.
protobuf:test-compile compiles test .proto definitions into Java files and attaches the generated Java test sources to the project.
protobuf:compile-cpp compiles main .proto definitions into C++ files and attaches the generated C++ sources to the project.
protobuf:test-compile-cpp compiles test .proto definitions into C++ files and attaches the generated C++ test sources to the project.
protobuf:compile-python compiles main .proto definitions into Python files and attaches the generated Python sources to the project.
protobuf:test-compile-python compiles test .proto definitions into Python files and attaches the generated Python test sources to the project.
protobuf:compile-csharp compiles main .proto definitions into C# files and attaches the generated C# sources to the project.
protobuf:test-compile-csharp compiles test .proto definitions into C# files and attaches the generated C# test sources to the project.
protobuf:compile-js compiles main .proto definitions into JavaScript files and attaches the generated JavaScript sources to the project.
protobuf:test-compile-js compiles test .proto definitions into JavaScript files and attaches the generated JavaScript test sources to the project.
protobuf:compile-javanano uses JavaNano generator (requires protobuf compiler version 3 or above) to compile main .proto definitions into Java files and attaches the generated Java sources to the project.
protobuf:test-compile-javanano uses JavaNano generator (requires protobuf compiler version 3 or above) to compile test .proto definitions into Java files and attaches the generated Java test sources to the project.
protobuf:compile-custom compiles main .proto definitions using a custom protoc plugin.
protobuf:test-compile-custom compiles test .proto definitions using a custom protoc plugin.
dependency:analyze analyzes the dependencies of this project and determines which are: used and declared; used and undeclared; unused and declared.
dependency:analyze-dep-mgt analyzes your projects dependencies and lists mismatches between resolved dependencies and those listed in your dependencyManagement section.
dependency:analyze-only is the same as analyze, but is meant to be bound in a pom. It does not fork the build and execute test-compile.
dependency:analyze-report analyzes the dependencies of this project and produces a report that summarises which are: used and declared; used and undeclared; unused and declared.
dependency:analyze-duplicate analyzes the and tags in the pom.xml and determines the duplicate declared dependencies.
dependency:build-classpath tells Maven to output the path of the dependencies from the local repository in a classpath format to be used in java -cp. The classpath file may also be attached and installed/deployed along with the main artifact.
dependency:copy takes a list of artifacts defined in the plugin configuration section and copies them to a specified location, renaming them or stripping the version if desired. This goal can resolve the artifacts from remote repositories if they don't exist in either the local repository or the reactor.
dependency:copy-dependencies takes the list of project direct dependencies and optionally transitive dependencies and copies them to a specified location, stripping the version if desired. This goal can also be run from the command line.
dependency:display-ancestors displays all ancestor POMs of the project. This may be useful in a continuous integration system where you want to know all parent poms of the project. This goal can also be run from the command line.
dependency:get resolves a single artifact, eventually transitively, from a specified remote repository.
dependency:go-offline tells Maven to resolve everything this project is dependent on (dependencies, plugins, reports) in preparation for going offline.
dependency:list alias for resolve that lists the dependencies for this project.
dependency:list-classes displays the fully package-qualified names of all classes found in a specified artifact.
dependency:list-repositories displays all project dependencies and then lists the repositories used.
dependency:properties set a property for each project dependency containing the to the artifact on the file system.
dependency:purge-local-repository tells Maven to clear dependency artifact files out of the local repository, and optionally re-resolve them.
dependency:resolve tells Maven to resolve all dependencies and displays the version. JAVA 9 NOTE: will display the module name when running with Java 9.
dependency:resolve-plugins tells Maven to resolve plugins and their dependencies.
dependency:sources tells Maven to resolve all dependencies and their source attachments, and displays the version.
dependency:tree displays the dependency tree for this project.
dependency:unpack like copy but unpacks.
dependency:unpack-dependencies like copy-dependencies but unpacks.
# NODE_VERSION=16.15.0
NODE_VERSION=14.21.1-alpine
docker run --volume $PWD:/app -it node:$NODE_VERSION /bin/bash
cd /app
node --version
command line arguments
javascript REPL
node
RUNNING YOUR CODE
# Evaluates the current argument as JavaScript
node --eval
# Checks the syntax of a script without executing it
node --check
# Opens the node.js REPL (Read-Eval-Print-Loop)
node --interactive
# Pre-loads a specic module at start-up
node --require
# Silences the deprecation warnings
node --no-deprecation
# Silences all warnings (including deprecations)
node --no-warnings
# Environment variable that you can use to set command line optionsecho$NODE_OPTIONS
CODE HYGIENE
# Emits pending deprecation warnings
node --pending-deprecation
# Prints the stack trace for deprecations
node --trace-deprecation
Throws error on deprecation
node --throw-deprecation
Prints the stack trace for warnings
node --trace-warnings
INITIAL PROBLEM INVESTIGATION
# Generates node report on signal
node --report-on-signal
# Generates node report on fatal error
node --report-on-fatalerror
# Generates diagnostic report on uncaught exceptions
node --report-uncaught-exception
CONTROLLING/INVESTIGATING MEMORY USE
# Sets the size of the heap
--max-old-space-size
# Turns on gc logging
--trace_gc
# Enables heap proling
--heap-prof
# Generates heap snapshot on specied signal
--heapsnapshot-signal=signal
CPU PERFORMANCE INVESTIGATION
# Generates V8 proler output.
--prof
# Process V8 proler output generated using --prof
--prof-process
# Starts the V8 CPU proler on start up, and write the CPU prole to disk before exit
--cpu-prof
DEBUGGING
# Activates inspector on host:port and break at start of user script
--inspect-brk[=[host:]port]
# Activates inspector on host:port (default: 127.0.0.1:9229)
--inspect[=[host:]port]
npm
config
npm config ls
npm config list
npm registry
remove registry
npm config delete registry
set registry
# how to set registry
npm config set strict-ssl false
npm config set registry https://registry.npmjs.org/
or adjust environment
NPM_CONFIG_REGISTRY=https://registry.npmjs.org/
add additional registry
npm config set @my-personal-repo:registry https://ci.ubs.com/nexus/repository/cds-npm
# best practice# package-lock.json must have be present in root ( under git control )
npm ci
permission denied for folder /usr/lib
# create new folder where node will place all packages
mkdir ~/.npm-global
# Configure npm to use new folder
npm config set prefix '~/.npm-global'# update your settings in ```vim ~/.profile```export PATH=~/.npm-global/bin:$PATH
massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API /
Query Method: CQL and Thrift,
replication: peer-to-peer,
written in: Java,
Concurrency: tunable consistency,
Misc: built-in data compression, MapReduce support, primary/secondary indexes, security features.
Cassandra-compatible column store, with consistent low latency and more transactions per second. Designed with a thread-per-core model to maximize performance on modern multicore hardware. Predictable scaling. No garbage collection pauses, and faster compaction.
Accumulo is based on BigTable and is built on top of Hadoop, Zookeeper, and Thrift. It features improvements on the BigTable design in the form of cell-based access control, improved compression, and a server-side programming mechanism that can modify key/value pairs at various points in the data management process.
Splice Machine is an RDBMS built on Hadoop, HBase and Derby. Scale real-time applications using commodity hardware without application rewrites, Features: ACID transactions, ANSI SQL support, ODBC/JDBC, distributed computing
massively scalable in-memory and persistent storage DBMS for analytics on market data (and other time series data). APIs: C/C++, Java Native Interface (JNI), C#/.NET), Python, SQL (native, ODBC, JDBC), Data layout: row, columnar, hybrid,
Written in: C,
Replication: master/slave, cluster, sharding,
Concurrency: Optimistic (MVCC) and pessimistic (locking)
data store for business intelligence (OLAP) queries on event data. Low latency (real-time) data ingestion, flexible data exploration, fast data aggregation. Scaled to trillions of events & petabytes. Most commonly used to power user-facing analytic applications.
API: JSON over HTTP, APIs: Python, R, Javascript, Node, Clojure, Ruby, Typescript + support SQL queries
Elassandra is a fork of Elasticsearch modified to run on top of Apache Cassandra in a scalable and resilient peer-to-peer architecture. Elasticsearch code is embedded in Cassanda nodes providing advanced search features on Cassandra tables and Cassandra serve as an Elasticsearch data and configuration store.
[OpenNeptune, Qbase, KDI]
A fully managed Document store with multi-master replication across data centers. Originally part of Google App Engine, it also has REST and gRPC APIs. Now Firestore?!
is a fully managed, globally distributed NoSQL database perfect for the massive scale and low latency needs of modern applications. Guarantees: 99.99% availability, 99% of reads at <10ms and 99% of writes at <15ms. Scale to handle 10s-100s of millions of requests/sec and replicate globally with the click of a button. APIs: .NET, .NET Core, Java, Node.js, Python, REST. Query: SQL.
a 100% native .NET Open Source NoSQL Document Database (Apache 2.0 License).
It also supports SQL querying over JSON Documents.
Data can also be accessed through LINQ & ADO.NET.
NosDB also provides strong server-side and client-side caching features by integrating NCache.
Query Method: Full Text Search and Structured Query, XPath, XQuery, Range, Geospatial, Bitemporal
Written in: C++
Concurrency: Shared-nothing cluster, MVCC
Misc: Petabyte-scalable and elastic (on premise in the cloud), ACID + XA transactions, auto-sharding, failover, master slave
replication (clusters),
replication (within cluster), high availablity, disaster recovery, full and incremental backups, government grade security at the doc level, developer community »
written in pure JavaScript. It queries the collections with a gremlin-like DSL that uses MongoDB's API methods, but also provides joining. The collections extend the native array objects, which gives the overall ODM a good performance. Queries 500.000 elements in less then a second.
NoSQL database for Node.js in pure javascript. It implements the most commonly used subset of MongoDB's API and is quite fast (about 25,000 reads/s on a 10,000 documents collection with indexing).
Architected to unify the best of search engine, NoSQL and NewSQL DB technologies.
API: REST and many languages.
Query method: SQL.
Written in C++.
Concurrency: MVCC.
Misc: ACID transactions, data distribution via consistent hashing, static and dynamic schema support, in-memory processing. Freeware + Commercial License
Node.js asynchronous NoSQL embedded database for small websites or projects. Database supports: insert, update, remove, drop and supports views (create, drop, read).
Written in JavaScript, no dependencies, implements small
100% JavaScript automatically synchronizing multi-model database with a SQL like syntax (JOQULAR) and swapable persistence stores. It supports joins, nested matches, projections or live object result sets, asynchronous cursors, streaming analytics, 18 built-in predicates, in-line predicates, predicate extensibility, indexable computed values, fully indexed Dates and Arrays, built in statistical sampling. Persistence engines include files, Redis, LocalStorage, block storage, and more.
Collections of free form entities (row key, partition key, timestamp). Blob and Queue Storage available, 3 times redundant. Accessible via REST or ATOM.
Fast and web-scale database. RAM or SSD. Predictable performance; achieves 2.5 M TPS (reads and writes), 99% under 1 ms. Tunable consistency. Replicated, zero configuration, zero downtime, auto-clustering, rolling upgrades, Cross Datacenter
Replication (XDR).
Written in: C. APIs: C, C#, Erlang, Go, Java, Libevent, Node, Perl, PHP, Python, Ruby.
Immediate consistency sharded KV store with an eventually consistent AP store bringing eventual consistency issues down to the theoretical minimum. It features efficient record coalescing. GenieDB speaks SQL and co-exists / do intertable joins with SQL RDBMs.
Key-Value database that was written as part of SQLite4,
They claim it is faster then LevelDB.
Instead of supporting custom comparators, they have a recommended data encoding for keys that allows various data types to be sorted.
data store for Windows Phone 8, Windows RT, Win32 (x86 & x64) and .NET. Provides for key-value and multiple segmented key access. APIs for C#, VB, C++, C and HTML5/JavaScript.
Written in pure C for high performance and low footprint. Supports async and synchronous operations with 2GB max record size.
Written in C,C++. Fast key/value store with a parameterized B+-tree. Keys are "typed" (i.e. 32bit integers, floats, variable length or fixed length binary data). Has built-in analytical functions like SUM, AVERAGE etc.
A pure key value store with optimized b+tree and murmur hashing. (In the near future it will be a JSON document database much like mongodb and couchdb.)
peer-to-peer distributed in-memory (with persistence) datagrid that implements and expands on the concept of the Tuple Space. Has SQL Queries and ACID (=> NewSQL).
Key-Value concept. Variable number of keys per record. Multiple key values, Hierarchic records. Relationships. Diff. record types in same DB. Indexing: B*-Tree. All aspects configurable. Full scripting language. Multi-user ACID. Web interfaces (PHP, Perl, ActionScript) plus Windows client.
Distributed searchable key-value store. Fast (latency & throughput), scalable, consistent, fault tolerance, using hyperscpace hashing. APIs for C, C++ and Python.
Fast, open source, shared memory (using memory mapped files e.g. in /dev/shm or on SSD), multi process, hash table, e.g. on an 8 core i7-3720QM CPU @ 2.60GHz using /dev/shm, 8 processes combined have a 12.2 million / 2.5 to 5.9 million TPS read/write using small binary keys to a hash filecontaining 50 million keys. Uses sharding internally to mitigate lock contention.
data store developed by Symas for the OpenLDAP Project. It uses memory-mapped files, so it has the read performance of a pure in-memory database while still offering the persistence of standard disk-based databases, and is only limited to the size of the virtual address space, (it is not limited to the size of physical RAM)
Sophia is a modern embeddable key-value database designed for a high load environment. It has unique architecture that was created as a result of research and rethinking of primary algorithmical constraints, associated with a getting popular Log-file based data structures, such as LSM-tree. Implemented as a small C-
Key-value store, B+tree. Lightning fast reads+fast bulk loads. Memory-mapped files for persistent storage with all the speed of an in-memory database. No tuning conf required. Full ACID support. MVCC, readers run lockless. Tiny code,
written in C, compiles to under 32KB of x86-64 object code. Modeled after the BerkeleyDB API for easy migration from Berkeley-based code. Benchmarks against LevelDB, Kyoto Cabinet, SQLite3, and BerkeleyDB are available, plus full paper and presentation slides.
BinaryRage is designed to be a lightweight ultra fast key/value store for .NET with no dependencies. Tested with more than 200,000 complex objects
written to disk per second on a crappy laptop :-) No configuration, no strange driver/connector, no server, no setup - simply reference the dll and start using it in less than a minute.
Serenity database implements basic Redis commands and extends them with support of Consistent Cursors, ACID transactions, Stored procedures, etc. The database is designed to store data bigger then available RAM.
Written in C++. In-memory LRU cache with very small memory footprint. Works within fixed amount of memory. Cachelot has a C++ cache library and stand-alone server on top of it.
Use a JSON encoded file to automatically save a JavaScript value to disk whenever that value changes. A value can be a Javascript: string, number, boolean, null, object, or an array. The value can be structured in an array or an object to allow for more complex
data stores. These structures can also be nested. As a result, you can use this module as a simple document store for storing semistructured data.
InfinityDB is an all-Java embedded DBMS with access like java.util.concurrent.ConcurrentNavigableMap over a tuple space, enhanced for nested Maps, LOBs, huge sparse arrays, wide tables with no size constraints. Transactions, compression, multi-core
concurrency, easy schema evolution. Avoid the text/binary trap: strongly-typed, fine-grained access to big structures. 1M ops/sec. Commercial, closed source, patented.
data store for multi-dimensional data. BBoxDB enhances the key-value data model by a bounding box, which describes the location of a value in an n-dimensional space. Data can be efficiently retrieved using hyperrectangle queries. Spatial joins and dynamic data redistribution are also supported.
API: Java,
Protocol: asynchronous binary, Data model: Key-bounding-box-value, Scaling: **Auto-Sharding,
A HTTP based, user facing, RESTful NoSQL cache server based on HAProxy. It can be used as an internal NoSQL cache sits between your application and database like Memcached or Redis as well as a user facing NoSQL cache that sits between end user and your application. It supports headers, cookies, so you can store per-user data to same endpoint.
RDF enterprise database management system. It is cross-platform and can be used with most programming languages. Main features: high performance, guarantee database transactions with ACID, secure with ACL's, SPARQL & SPARUL, ODBC & JDBC drivers, RDF & RDFS. »
WhiteDB is a fast lightweight graph/N-tuples shared memory database library
written in C with focus on speed, portability and ease of use. Both for Linux and Windows, dual licenced with GPLv3 and a free nonrestrictive royalty-free commercial licence.
API: REST, Binary Protocol, Java, Node.js, Tinkerpop Blueprints, Python, PHP, Go, Elixir, etc., Schema: Has features of an Object-Database, DocumentDB, GraphDB and Key-Value DB,
Written in: Java,
Query Method: SQL, Gremlin, SparQL,
Concurrency: MVCC, tuneable, Indexing: Primary, Secondary, Composite indexes with support for Full-Text and Spatial,
Replication: Master-Masterfathomdb + sharding,
Misc: Really fast, Lightweight, ACID with recovery.
API: JavaScript Schema: Has features of an Object-Database, DocumentDB, GraphDB and Key-Value DB
Written in: JavaScript
Query Method: JavaScript
Concurrency: Eventual consistency with hybrid vector/timestamp/lexical conflict resolution Indexing: O(1) key/value, supports multiple indices per record
CortexDB is a dynamic schema-less multi-model data base providing nearly all advantages of up to now known NoSQL data base types (key-value store, document store, graph DB, multi-value DB, column DB) with dynamic re-organization during continuous operations, managing analytical and transaction data for agile software configuration,change requests on the fly, self service and low footprint.
Oracle NoSQL Database is a distributed key-value database with support for JSON docs. It is designed to provide highly reliable, scalable and available data storage across a configurable set of systems that function as storage nodes. NoSQL and the Enterprise Data is stored as key-value pairs, which are
written to particular storage node(s), based on the hashed value of the primary key. Storage nodes are replicated to ensure high availability, rapid failover in the event of a node failure and optimal load balancing of queries.
GraphDB + RDBMS + KV Store + Document Store. Alchemy Database is a low-latency high-TPS NewSQL RDBMS embedded in the NOSQL datastore redis. Extensive datastore-side-scripting is provided via deeply embedded Lua. Bought and integrated with Aerospike.
WonderDB is fully transactional, distributed NewSQL database implemented in java based on relational architectures.
So you can get best of both worlds, sql, joins and ease of use from SQL and distribution,
replication and sharding from NoSQL movement. Tested performance is over 60K per node with Amazon m3.xlarge VM.
A new concept to ‘NoSQL’ databases where a memory allocator and a transactional database are melted together into an almost seamless whole.
The programming model uses variants of well-known memory allocation calls like ‘new’ and ‘delete’ to manage the database.
The result is very fast, natural to use, reliable and scalable.
It is especially good in Big Data, data collection, embedded, high performance, Internet of Things (IoT) or mobile type applications.
Protocol: Java, C#, C++, Python. Schema: language class model (easy changable). Modes: always consistent and eventually consistent
Replication: synchronous fault tolerant and peer to peer asynchronous.
Concurrency: optimistic and object based locks. Scaling: can add physical nodes on fly for scale out/inand migrate objects between nodes without impact to application code.
Misc: MapReduce via parallel SQL like query across logical database groupings.
API: Languages: Java, C#, C++, Python, Smalltalk, SQL access through ODBC. Schema: native language class model, direct support for references, interoperable across all language bindings. 64 bit unique object ID (OID) supports multi exa-byte. Platforms: 32 and 64 bit Windows, Linux, Mac OSX, *Unix. Modes: always consistent (ACID).
Concurrency: locks at cluster of objects (container) level. Scaling: unique distributed architecture, dynamic addition/removal of clients & servers, cloud environment ready.
Replication: synchronous with quorum fault tolerant across peer to peer partitions.
Misc: compact data, B-tree indexes, LINQ queries, 64bit object identifiers (Oid) supporting multi millions of databases and high performance. Deploy with a single DLL of around 400KB.
Written in: 100% C#, The HSS DB v3.0 (HighSpeed-Solutions Database), is a client based, zero-configuration, auto schema evolution, acid/transactional, LINQ Query, DBMS for Microsoft .NET 4/4.5, Windows 8 (Windows Runtime), Windows Phone 7.5/8, Silverlight 5, MonoTouch for iPhone and Mono for Android
Newt DB leverages the pluggable storage layer of ZODB to use RelStorage to store data in Postgres. Newt adds conversion of data from the native serialization used by ZODB to JSON, stored in a Postgres JSONB column. The JSON data supplements the native data to support indexing, search, and access from non-Python applications. It adds a search API for searching the Postgres JSON data and returning persistent objects.
An object database engine that currently runs on .NET, Mono, Silverlight,Windows Phone 7, MonoTouch, MonoAndroid, CompactFramework; It has implemented a Sync Framework Provider and can be synchronized with MS SQLServer;
is a lightweight object-oriented database for .NET with support for Silverlight and Windows Phone 7. It features in-memory keys and indexes, triggers, and support for compressing and encrypting the underlying data.
An embedded object database designed for mobile apps targetting .net and Mono runtimes. Supports .net/mono, Xamarin (iOS and Android), Windows 8.1/10, Windows Phone 8.1. Simple API, built on top of json.net and has a simple but effective indexing mechanism. Development is focussed on being lightweight and developer friendly. Has transaction support. Open-source and free to use.
EyeDB is an LGPL OODBMS, provides an advanced object model (inheritance, collections, arrays, methods, triggers, constraints, reflexivity), an object definition language based on ODMG ODL, an object query and manipulation language based on ODMG OQL. Programming interfaces for C++ and Java.
Object-Oriented Database designed to support the maintenance and sharing of knowledge bases. Optimized for pointer-intensive data structures used by semantic networks, frame systems, and many intelligent agent applications.
Ninja Database Pro is a .NET ACID compliant relational object database that supports transactions, indexes, encryption, and compression. It currently runs on .NET Desktop Applications, Silverlight Applications, and Windows Phone 7 Applications.
Language and Object Database, can be viewed as a Database Development Framework. Schema: native language class model with relations + various indexes. Queries: language build in + a small Prolog like DSL Pilog.
Concurrency: synchronization + locks.
Replication, distribution and fault tolerance is not implemented per default but can be implemented with native functionality.
In-Memory Computing Platform built on Apache® Ignite™ to provide high-speed transactions with ACID guarantees, real-time streaming, and fast analytics in a single, comprehensive data access and processing layer. The distributed in-memory key value store is ANSI SQL-99 compliant with support for SQL and DML via JDBC or ODBC.
API: Java, .NET, and C++. Minimal or no modifications to the application or database layers for architectures built on all popular RDBMS, NoSQL or Apache™ Hadoop® databases.
data store. Accessed via SQL and has builtin BLOB support. Uses the cluster state implementation and node discovery of Elasticsearch. License: Apache 2.0,
Oracle Coherence offers distributed, replicated, multi-datacenter, tiered (off-heap/SSD) and near (client) caching. It provides distributed processing, querying, eventing, and map/reduce, session management, and prorogation of database updates to caches. Operational support provided by a Grid Archive deployment model.
GemFire offers in-memory globally distributed data management with dynamic scalability, very high performance and granular control supporting the most demanding applications. Well integrated with the Spring Framework, developers can quickly and easily provide sophisticated data management for applications. With simple horizontal scale-out, data latency caused by network roundtrips and disk I/O can be avoided even as applications grow.
Hazelcast is a in-memory data grid that offers distributed data in Java with dynamic scalability under the Apache 2 open source license. It provides distributed data structures in Java in a single Jar file including hashmaps, queues, locks, topics and an execution service that allows you to simply program these data structures as pure java objects, while benefitting from symmetric multiprocessing and cross-cluster shared elastic memory of very high ingest data streams and very high transactional loads.
written in XQuery, using XSLT, XHTML, CSS, and Javascript (for AJAX functionality). (1.4) adds a new full text search index based on Apache Lucene, a lightweight URL rewriting and MVC framework, and support for XProc.
Misc: ACID transactions, security, indices, hot backup. Flexible XML processing facilities include W3C XQuery implementation, tight integration of XQuery with full-text search facilities and a node-level update language.
BaseX is a fast, powerful, lightweight XML database system and XPath/XQuery processor with highly conformant support for the latest W3C Update and Full Text Recommendations. Client/Server architecture, ACID transaction support, user management, logging, Open Source, BSD-license,
API: Java. The application and database management system in one. Collects data as multiple XML files on the disk. Implements facet-oriented data model. Each data object is considered as an universal facet container. The end-user can design and evolve data objects individually through the GUI without any coding by adding/removing facets to/from it.
Postrelational System. Multidimensional array APIs, Object APIs, Relational Support (Fully SQL capable JDBC, ODBC, etc.) and Document APIs are new in the upcoming 2012.2.x versions. Availible for Windows, Linux and OpenVMS.
: Short description: Rasdaman is a scientific database that allows to store and retrieve multi-dimensional raster data (arrays) of unlimited size through an SQL-style query language.
API: C++/Java,
Written in C++,
Query method: SQL-like query language rasql, as well as via OGC standards WCPS, WCS, WPS link2
(Reality NPS): The original MultiValue dataset database, virtual machine, enquiry and rapid development environment. Delivers ultra efficiency, scalability and resilience while extended for the web and with built-in auto sizing, failsafe and more. Interoperability includes Web Services - Java Classes, RESTful, XML, ActiveX, Sockets, .NetLanguages, C and, for those interoperate with the world of SQL, ODBC/JDBC with two-way transparent SQL data access.
Supports nested data. Fully automated table space allocation.
Concurrency control via task locks, file locks & shareable/exclusive record locks. Case insensitivity option. Secondary key indices. Integrated data
replication. QMBasic programming language for rapid development. OO programming integrated into QMBasic. QMClient connectivity from Visual Basic, PowerBasic, Delphi, PureBasic, ASP, PHP, C and more. Extended multivalue query language.
Hybrid database / search engine system with characteristics of multi-value, document, relational, XML and graph databases. Used in production since 1985 for high-performance search and retrieve solutions. Full-text search, text classification, similarity search, results ranking, real time facets, Unicode, Chinese word segmentation, and more. Platforms: Windows, Linux, AIX and Solaris.
(by Microsoft) ISAM storage technology. Access using index or cursor navigation. Denormalized schemas, wide tables with sparse columns, multi-valued columns, and sparse and rich indexes. C# and Delphi drivers available. Backend for a number of MS Products as Exchange.
jBASE is an application platform and database that allows normal MultiValue (MV) applications to become native Windows, Unix or Linux programs. Traditional MV features are supported, including BASIC, Proc, Paragraph, Query and Dictionaries. jBASE jEDI Architecture, allows you to store data in any database, such as Microsoft SQL, Oracle and DB2. jBASE jAgent supports BASIC, C, C++, .NET, Java and REST APIs. Additional features include dynamic objects, encryption, case insensitivity, audit logging and transaction journaling for online backup and disaster recovery.
Distributed DB designed to store and analyze high-frequency time-series data at scale. Includes a large set of built-in features: Rule Engine, Visualization, Data Forecasting, Data Mining.
API: RESTful API, Network API, Data API, Meta API, SQL API Clients: R, Java, Ruby, Python, PHP, Node.js
Enterprise-grade NoSQL time series database optimized specifically for IoT and Time Series data. It ingests, transforms, stores, and analyzes massive amounts of time series data. Riak TS is engineered to be faster than Cassandra.
APIs: C++, Navigational C. Embedded Solution that is ACID Compliant with Multi-Core, On-Disk & In-Memory Support. Distributed Capabilities, Hot Online Backup, supports all Main Platforms. Supported B Tree & Hash Indexing.
NoSql, in-memory, flat-file, cloud-based. API interfaces. Small data footprint and very fast data retrieval. Stores 200 million records with 200 attributes in just 10GB. Retrieves 150 million records per second per CPU core. Often used to visualize big data on maps.
Applied Calculus implements persistent AVL Trees / AVL Databases. 14 different types of databases - represented as classes in both C# and Java. These databases perform transaction logging on the node file to ensure that failed transactions are backed out. Very fast on solid state storage (ca. 1780 transactions/second. AVL Trees considerably outperform B+ Trees on solid state. Very natural language interface. Each database is represented as a collection class that strongly resembles the corresponding class in Pure Calculus.
BayesDB, a Bayesian database table, lets users query the probable implications of their tabular data as easily as an SQL database lets them query the data itself. Using the built-in Bayesian Query Language (BQL), users with no statistics training can solve basic data science problems, such as detecting predictive relationships between variables, inferring missing values, simulating probable observations, and identifying statistically similar database entries.
A distributed database for many core devices.
GPUdb leverages many core devices such as NVIDIA GPUs to provide an unparallelled parallel database experience.
GPUdb is a scalable, distributed database with SQL-style query capability, capable of storing Big Data.
Developers using the GPUdb API add data, and query the data with operations like select, group by, and join.
GPUdb includes many operations not available in other "cloud database" offerings.
Mainly targeted to Silverlight/Windows Phone developers but its also great for any .NET application where a simple local database is required, extremely Lightweight - less than 50K, stores one table per file, including index, compiled versions for Windows Phone 7, Silverlight and .NET, fast, free to use in your applications
A digital brain, based on the language of thought (Mentalese), to manage relations and strategies (with thoughts/words/symbols) into a cognitive cerebral structure.
Programing language: MQL (Mentalese Query Language) for mental processes,
ACID transaction,
API: REST and web socket, Thoughts Performance: READ: 18035/s; WRITE: 416/s; Asynchronous Full JAVA
rm -rf ~/.kube/cache
oc get pods -v=6
oc get pods -v=7
oc get pods -v=8
# 1..10
oc --loglevel 9 get pod
ocp output
oc get pods --no-headers
oc get pods -o json
oc get pods -o jsonpath={.metadata.name}
oc get dc -o jsonpath-as-json={.items[*].spec.template.spec.volumes[*].persistentVolumeClaim.claimName}
oc get pods -o yaml
oc get pods -o wide
oc get pods -o name
oc get pods -o custom-columns=NAME:.metadata.name,RSRC:.metadata.resourceVersion
# or data in file: template.txt# NAME RSRC# metadata.name metadata.resourceVersion
oc get pods -o custom-columns-file=template.txt
REST api
print collaboration, output rest api call, print api calls
get in yaml, get source of resource, describe yaml
oc get -o yaml pod {name of the pod}
oc get -o json pod {name of the pod}
oc get -o json pod {name of the pod} --namespace one --namespace two --namespace three
secrets
create token for MapR
maprlogin password -user {mapruser}
# ticket-file will be created
check expiration date
maprlogin print -ticketfile /tmp/maprticket_1000 # or another filename
create secret from file
cat /tmp/maprticket_1000
# create secret from file ( default name )
oc create secret generic {name of secret/token} --from-file=/tmp/maprticket_1000 -n {project name}
# create secret from file with specifying the name - CONTAINER_TICKET ( oc describe {name of secret} )
oc create secret generic {name of secret/token} --from-file=CONTAINER_TICKET=/tmp/maprticket_1000 -n {project name}
get all information about current project, show all resources
oc get all
oc get deployment,pod,service,route,dc,pvc,secret -l deployment_name=name-of-my-deployment
oc get route/name-of-route --output json
restart pod
oc rollout latest "deploy-config-example"
restart deployment config
# DC_NAME - name of the Deployment/DeploymentConfig
oc rollout status dc $DC_NAME
oc rollout history dc $DC_NAME
oc rollout latest dc/$DC_NAME
oc get deployment $DC_NAME -o yaml | grep deployment | grep revision
oc import-image approved-apache --from=bitnami/apache:2.4 --confirm
oc import-image my-python --from=my-external.com/tdonohue/python-hello-world:latest --confirm
# if you have credential restrictions# oc create secret docker-registry my-mars-secret --docker-server=registry.marsrover.space --docker-username="[email protected]" --docker-password=thepasswordishere
!!! in case of any errors in process creation, pay attention to output of pods/....-build
build configs for images
oc get bc
oc describe bc/user-portal-dockerbuild
tag image stream tag image
oc tag my-external.com/tdonohue/python-hello-world:latest my-python:latest
# Tag a specific image
oc tag openshift/ruby@sha256:6b646fa6bf5e5e4c7fa41056c27910e679c03ebe7f93e361e6515a9da7e258cc yourproject/ruby:tip
# Tag an external container image
oc tag --source=docker openshift/origin-control-plane:latest yourproject/ruby:tip
# check tag
oc get is
connect to existing pod, execute command on remote pod, oc exec
oc get pods --field-selector=status.phase=Running
oc rsh <name of pod>
oc rsh -c <container name> pod/<pod name># connect to container inside the pod with multi container
POD_NAME=data-portal-67-dx
CONTAINER_NAME=data-portal-apache
oc exec -it -p $POD_NAME -c $CONTAINER_NAME /bin/bash
# or
oc exec -it $POD_NAME -c $CONTAINER_NAME /bin/bash
execute command in pod command
# example of executing program on pod: kafka-test-app
oc exec kafka-test-app "/usr/bin/java"
get environment variables
oc set env pod/$POD_DATA_API --list
copy file
# copy file from pod
oc cp <local_path><pod_name>:/<path> -c <container_name>
oc cp api-server-256-txa8n:usr/src/cert/keystore_server /my/local/path
# for OCP4 we should NOT to use leading slash like /usr/src.... # copy files from POD to locally
oc rsync /my/local/folder/ test01-mz2rf:/opt/app-root/src/
# copy file to pod
oc cp <pod_name>:/<path> -c <container_name><local_path>
forward port forwarding
oc port-forward <pod-name><ext-port>:<int-port>
functionoc-port-forwarding(){if [[ $#!= 3 ]]
thenecho"port forwarding for remote pods with arguments:"echo"1. project-name, like 'portal-stg-8' "echo"2. pod part of the name, like 'collector'"echo"3. port number like 5005"return 1
fi
oc login -u $USER_DATA_API_USER -p $USER_DATA_API_PASSWORD$OPEN_SHIFT_URL
oc project $1
POD_NAME=$(oc get pods | grep Running | grep $2| awk '{print $1}')echo$POD_NAME
oc port-forward $POD_NAME$3:$3
}
# list of config maps
oc get configmap
# describe one of the config map
oc get configmaps "httpd-config" -o yaml
oc describe configmap data-api-config
oc describe configmap gatekeeper-config
oc create configmap httpd-config-2 --from-file=httpd.conf=my-file-in-current-folder.txt
Grant permission to be able to access OpenShift REST API and discover services.
oc policy add-role-to-user view -n {name of application/namespace} -z default
information about current configuration
oc config view
the same as
cat ~/.kube/config/config
check accessible applications, ulr to application, application path
oc describe routes
Requested Host:
delete/remove information about some entities into project
oc delete {type} {type name}
buildconfigs
services
routes
...
Isio external service exposing
oc get svc istio-ingressgateway -n istio-system
expose services
if your service looks like svc/web - 172.30.20.243:8080
instead of external link like: http://gateway-myproject.192.168.42.43.nip.io to pod port 8080 (svc/gateway), then you can "expose" it for external world:
svn expose services/{app name}
svn expose service/{app name}
svn expose svc/{app name}
Liveness and readiness probes
# set readiness/liveness
oc set probe dc/{app-name} --liveness --readiness --get-url=http://:8080/health
# remove readiness/liveness
oc set probe dc/{app-name} --remove --liveness --readiness --get-url=http://:8080/health
# oc set probe dc/{app-name} --remove --liveness --readiness --get-url=http://:8080/health --initial-delay-seconds=30# Set a readiness probe to try to open a TCP socket on 3306
oc set probe rc/mysql --readiness --open-tcp=3306
Readiness probe will stop after first positive check Liveness probe will be executed again and again (period) during container lifetime
current ip address
minishift ip
open web console
minishift console
Kubernetes
print all context
kubectl config get-contexts
pring current context
kubectl config current-context
api version
kubectl api-versions
--> Success
Build scheduled, use 'oc logs -f bc/web' to track its progress.
Application is not exposed. You can expose services to the outside world by executing one or more of the commands below:
'oc expose svc/web'
Run 'oc status' to view your app.
job example
!!! openshift job starts only command - job will skip entrypoint
<htmllang="en"><head><metaname="google-signin-scope" content="profile email"><metaname="google-signin-client_id" content="273067202806-6cc49luinddclo4t6.apps.googleusercontent.com"><scriptsrc="https://apis.google.com/js/platform.js" asyncdefer></script></head><body><divclass="g-signin2" data-onsuccess="onSignIn" data-theme="dark">google button</div><script>functiononSignIn(googleUser){// Useful data for your client-side scripts:varprofile=googleUser.getBasicProfile();console.log("ID: "+profile.getId());// Don't send this directly to your server!console.log('Full Name: '+profile.getName());console.log('Given Name: '+profile.getGivenName());console.log('Family Name: '+profile.getFamilyName());console.log("Image URL: "+profile.getImageUrl());console.log("Email: "+profile.getEmail());// The ID token you need to pass to your backend:varid_token=googleUser.getAuthResponse().id_token;console.log("ID Token for backend: "+id_token);}</script><ahref="#" onclick="signOut();">Sign out</a><script>functionsignOut(){varauth2=gapi.auth2.getAuthInstance();auth2.signOut().then(function(){console.log('User signed out.');});}</script></body></html>
google rest api services, collaboration with google rest api service
# Cloud Console: Enable the YouTube Data API v3 for your project and get your API key.
YOUR_VIDEO_ID=....
YOUR_API_KEY=....
curl -X GET https://www.googleapis.com/youtube/v3/videos?part=statistics&id=${YOUR_VIDEO_ID}&key=${YOUR_API_KEY}
# activate api key
YOUR_API_KEY="AIzaSyDTE..."echo$YOUR_API_KEY# attempt to find place by name # x-www-browser https://developers.google.com/places/web-service/search
SEARCH_STRING="Fallahi%20Zaher%20Attorney"
curl -X GET "https://maps.googleapis.com/maps/api/place/findplacefromtext/json?input=${SEARCH_STRING}&inputtype=textquery&fields=place_id,photos,formatted_address,name,rating,geometry&key=${YOUR_API_KEY}"# place_id="ChIJl73rFVTf3IARQFQg3ZSOaKo"# detail about place (using place_id) including user's reviews# x-www-browser https://developers.google.com/places/web-service/details
curl -X GET "https://maps.googleapis.com/maps/api/place/details/json?place_id=${place_id}&fields=name,rating,review,formatted_phone_number&key=$YOUR_API_KEY"# unique field here - time
curl -X GET https://graph.facebook.com/v7.0/me?fields=id,last_name,name&access_token=${ACCESS_TOKEN}"
get ratings
# $PROFILE_ID/ratings?fields=reviewer,review_text,rating,has_review
curl -i -X GET \
"https://graph.facebook.com/v8.0/$PROFILE_ID/ratings?fields=reviewer%2Creview_text%2Crating%2Chas_review&access_token=$ACCESS_TOKEN"# https://developers.facebook.com/tools/explorer/?method=GET&path=$PROFILE_ID%2Fratings%3Ffields%3Drating%2Creview_text%2Creviewer&version=v8.0# https://developers.facebook.com/tools/explorer/${APP_ID}/?method=GET&path=${PROFILE_NAME}%3Ffields%3Dreview_text&version=v8.0
possible fields:
name
created_time
rating
review_text
recommendation_type
reviewer
has_review
{
"data": [
{
"created_time": "2020-08-17T20:40:26+0000",
"recommendation_type": "positive",
"review_text": "let's have a fun! it is a great company for that"
}
]
}
<html><body><ahref="https://www.linkedin.com/oauth/v2/authorization?response_type=code&client_id=78j2mw9cg7da1x&redirect_uri=http%3A%2F%2Fec2-52-29-176-43.eu-central-1.compute.amazonaws.com&state=my_unique_value_generated_for_current_user&scope=r_liteprofile%20r_emailaddress"> login with LinkedIn </a></body></html>
# list of devices
iw dev
# sudo apt-get install macchanger
macchanger -s wlp1s0
sudo ifconfig wlp1s0 down
# ip link set wlp1s0 down
sudo macchanger -r wlp1s0
sudo ifconfig wlp1s0 up
macchanger -s wlp1s0
list of all accessible wifi points
# force rescan
nmcli device wifi rescan
# all points
nmcli device wifi
# all fields
nmcli -f ALL device wifi
# all fields with using in script
nmcli -t -f ALL device wifi
nmcli -m multiline -f ALL device wifi
# alternative way
iwlist wlan0 scan
# alternative way
iw wlan0 scan
# alternative way
sudo apt install wavemon
fetch('https://api.ipify.org').then(response=>{if(!response.ok){thrownewError(`HTTP error! Status: ${response.status}`);}returnresponse.text();}).then(ip=>{console.log('Your IP address is:',ip);}).catch(error=>{console.error('There was an error fetching the IP address:',error);});


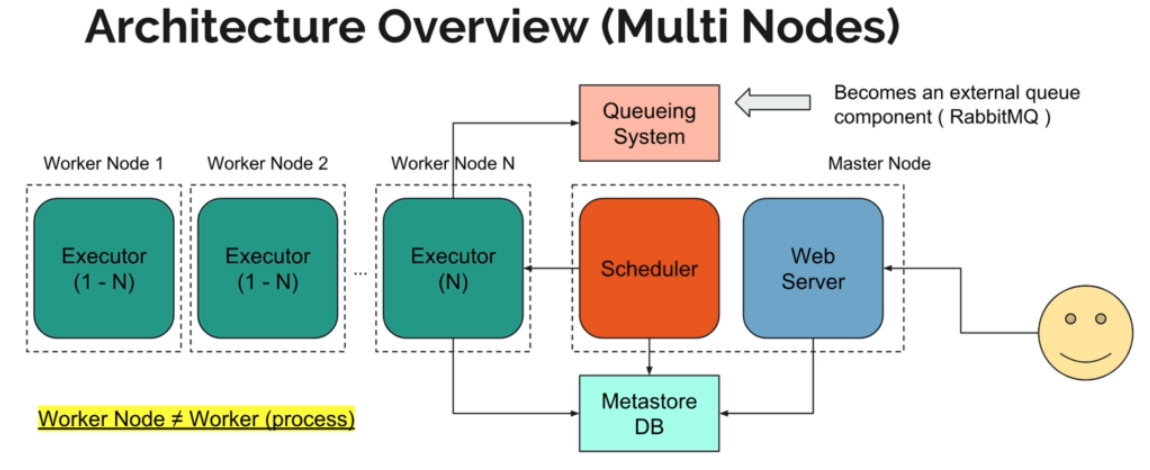
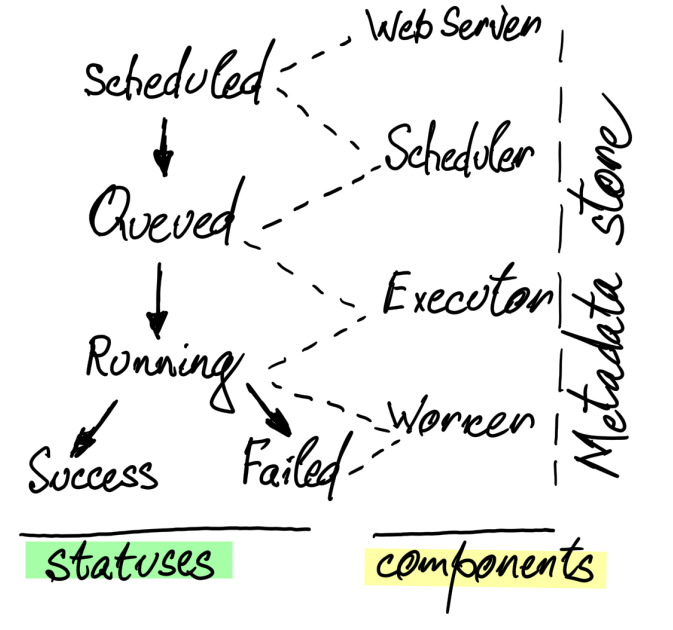
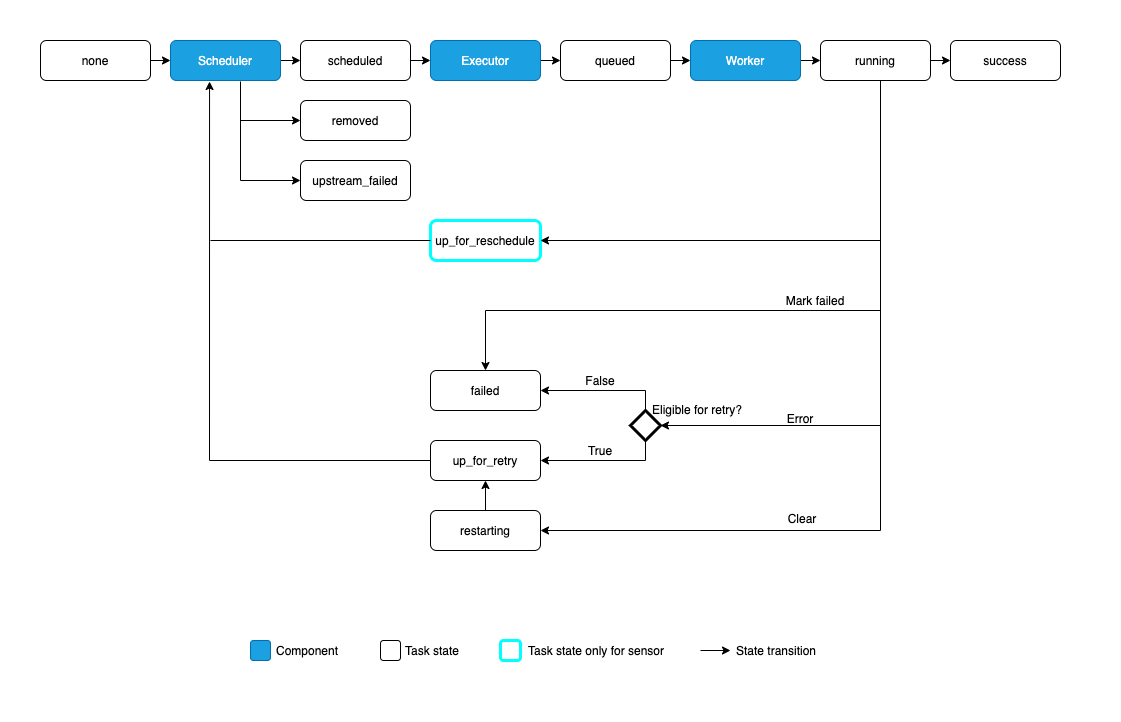

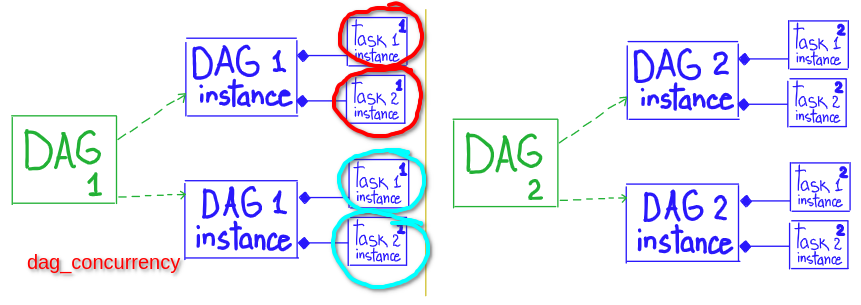
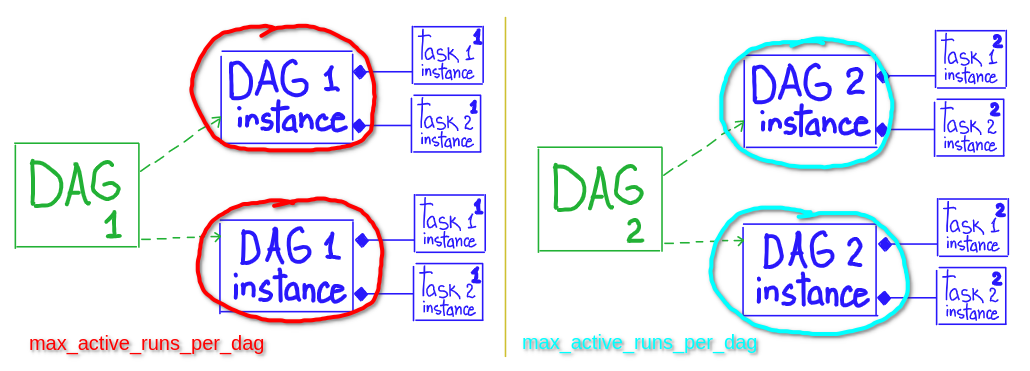
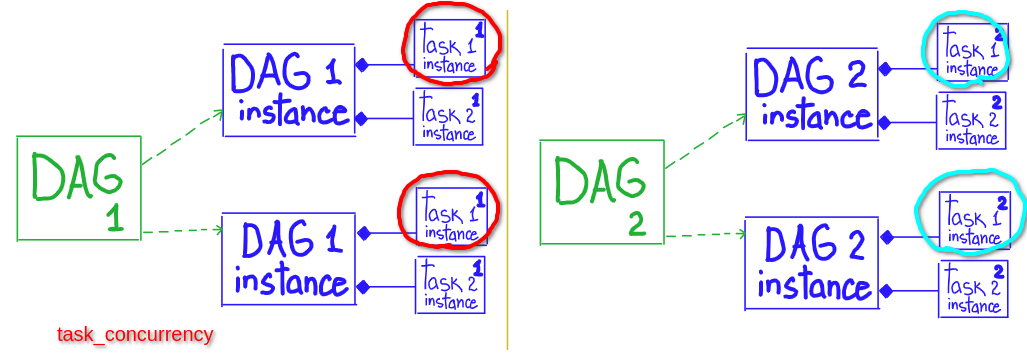
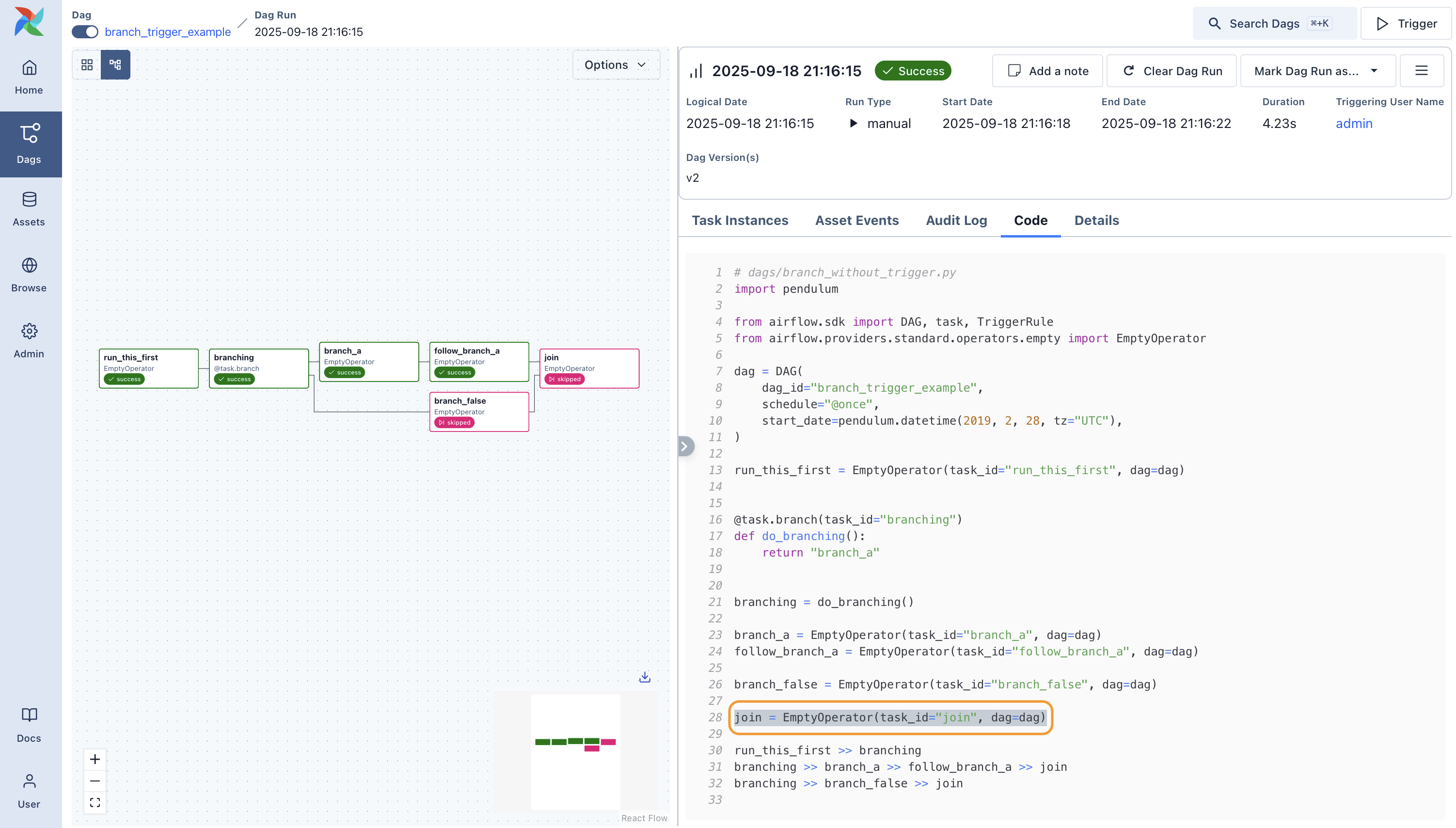
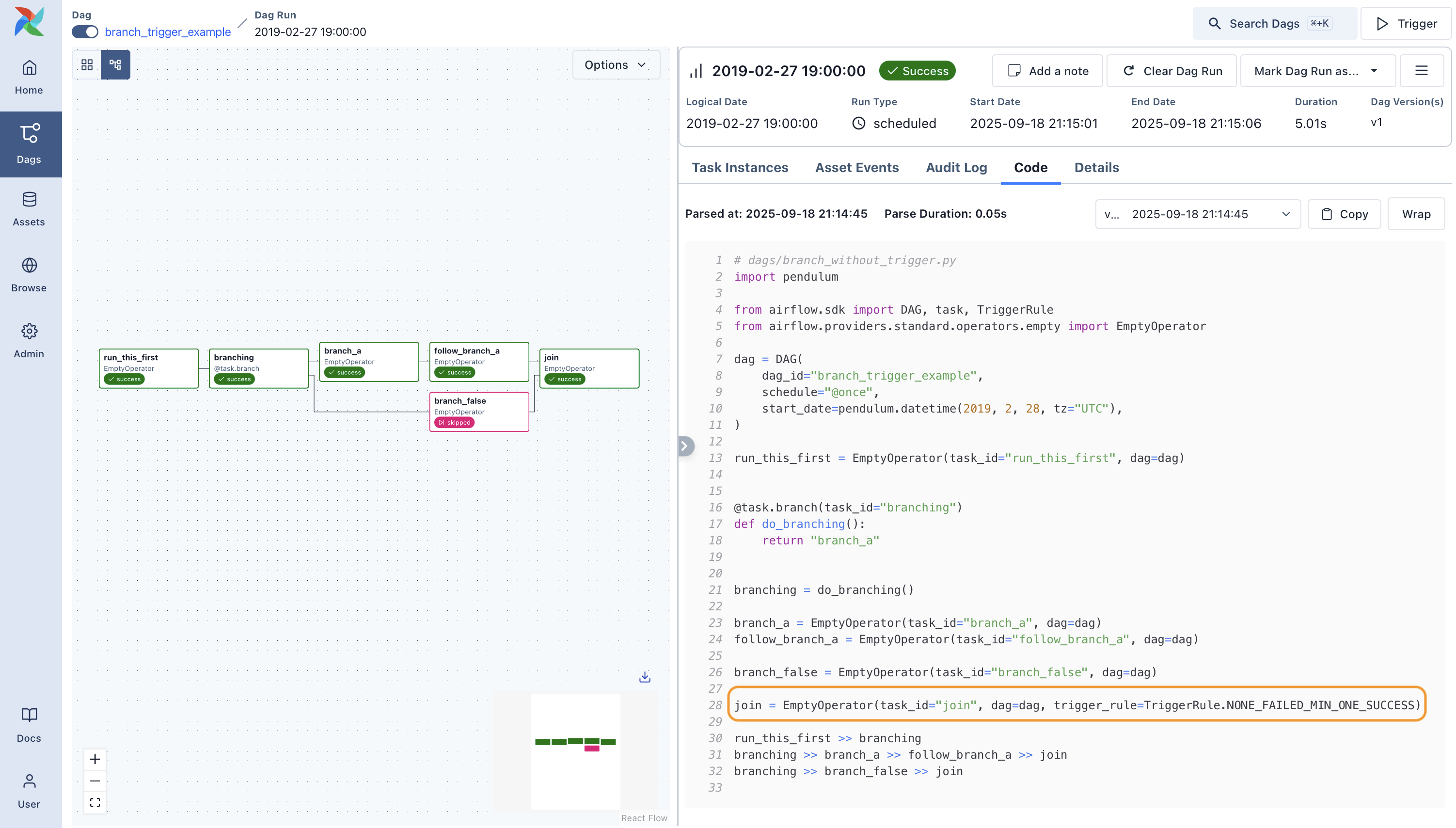
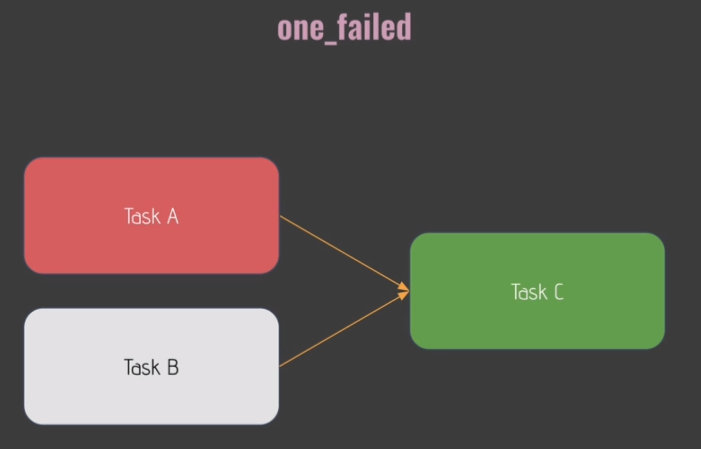
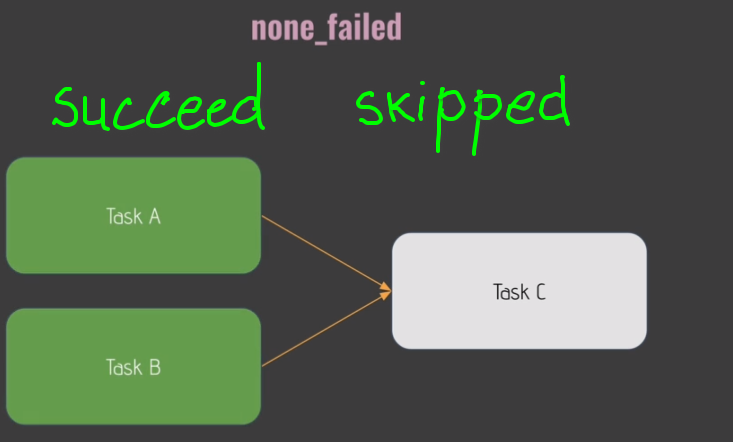
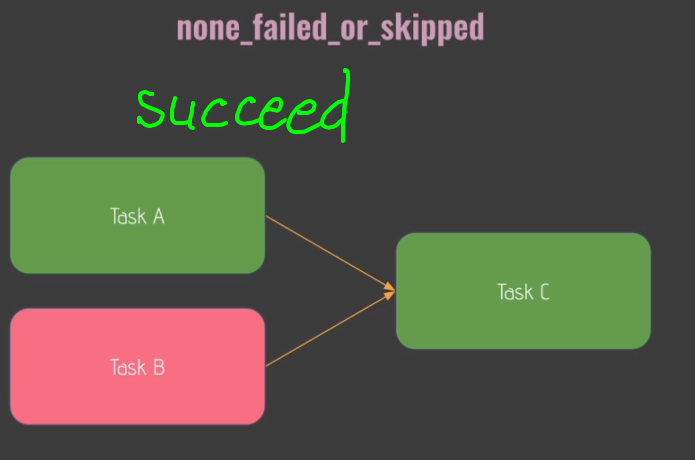
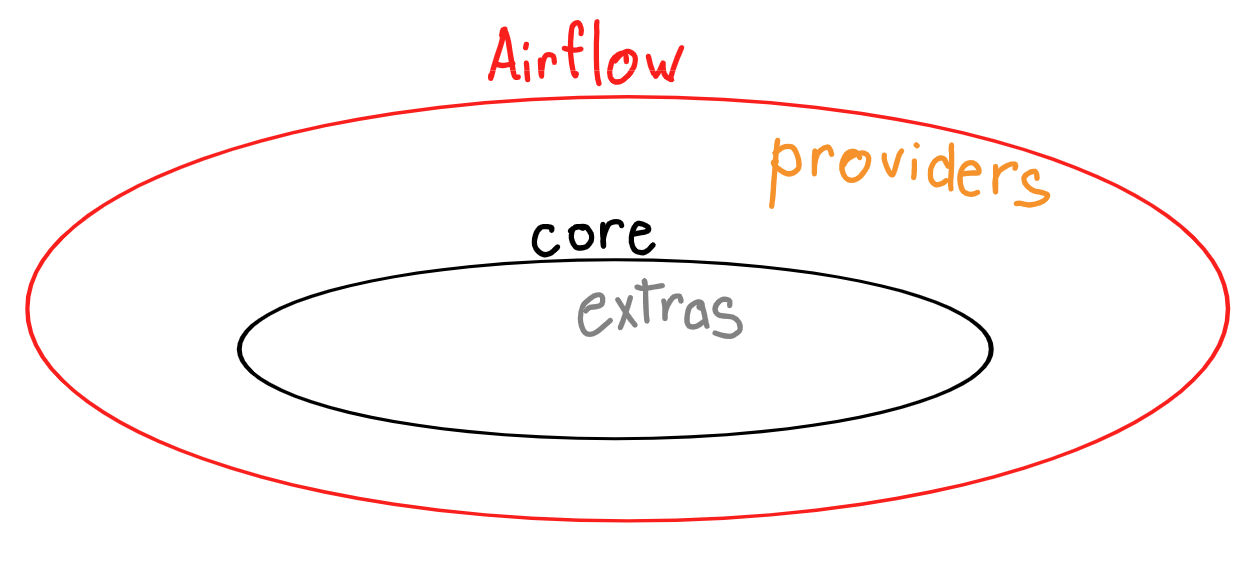

















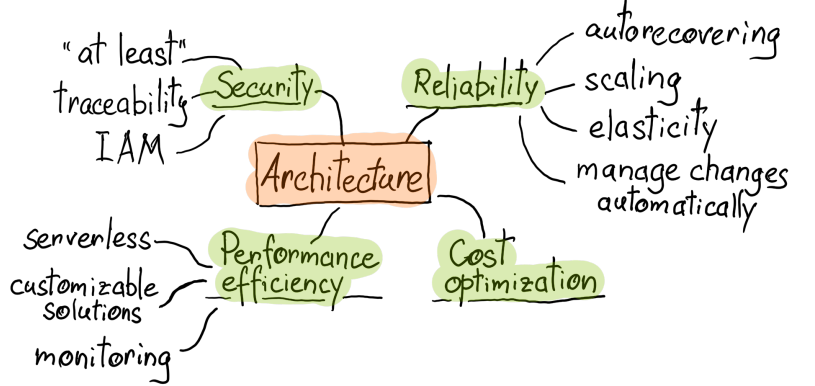

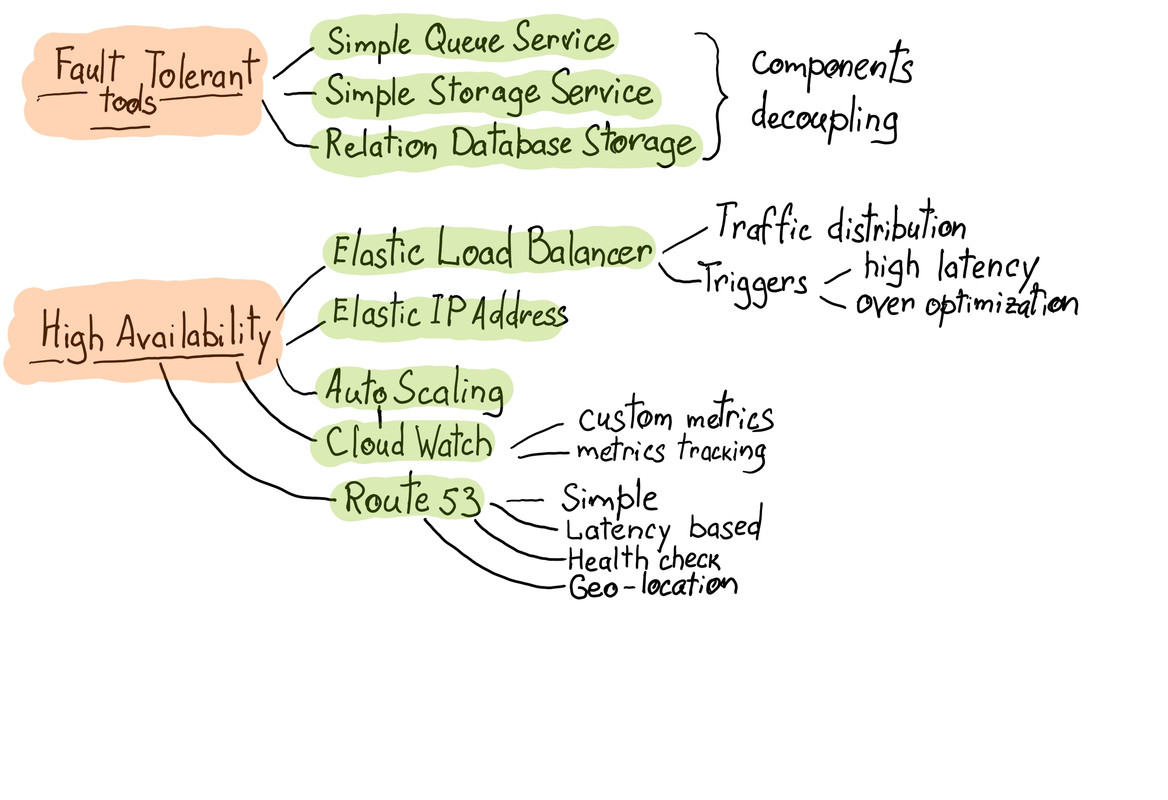
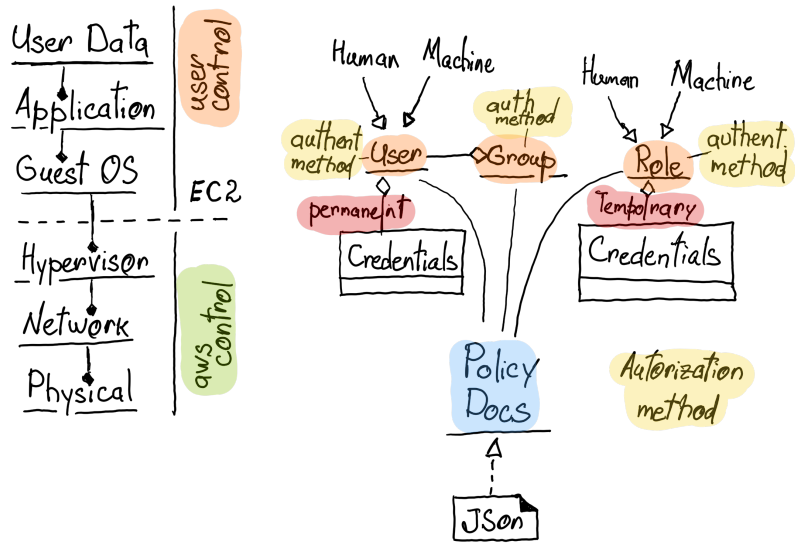
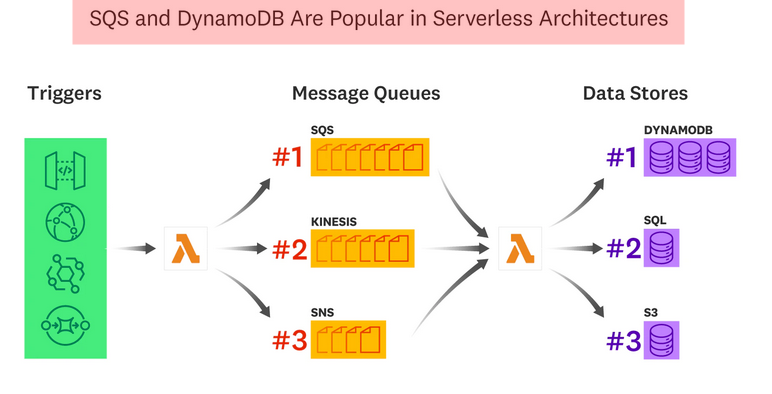





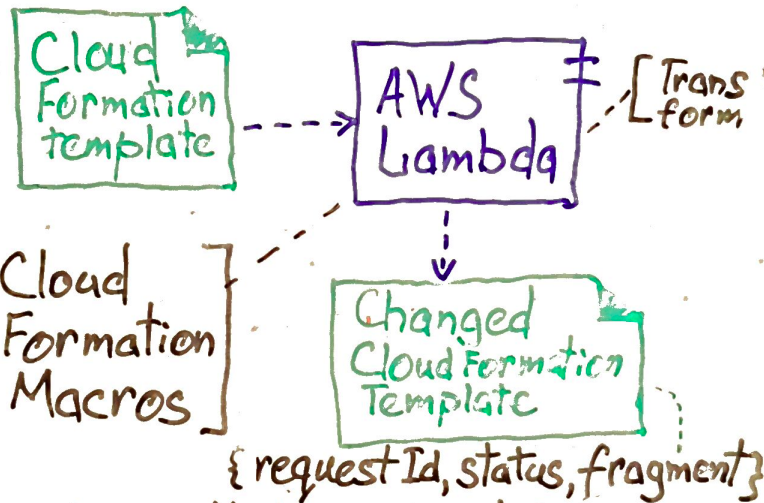




















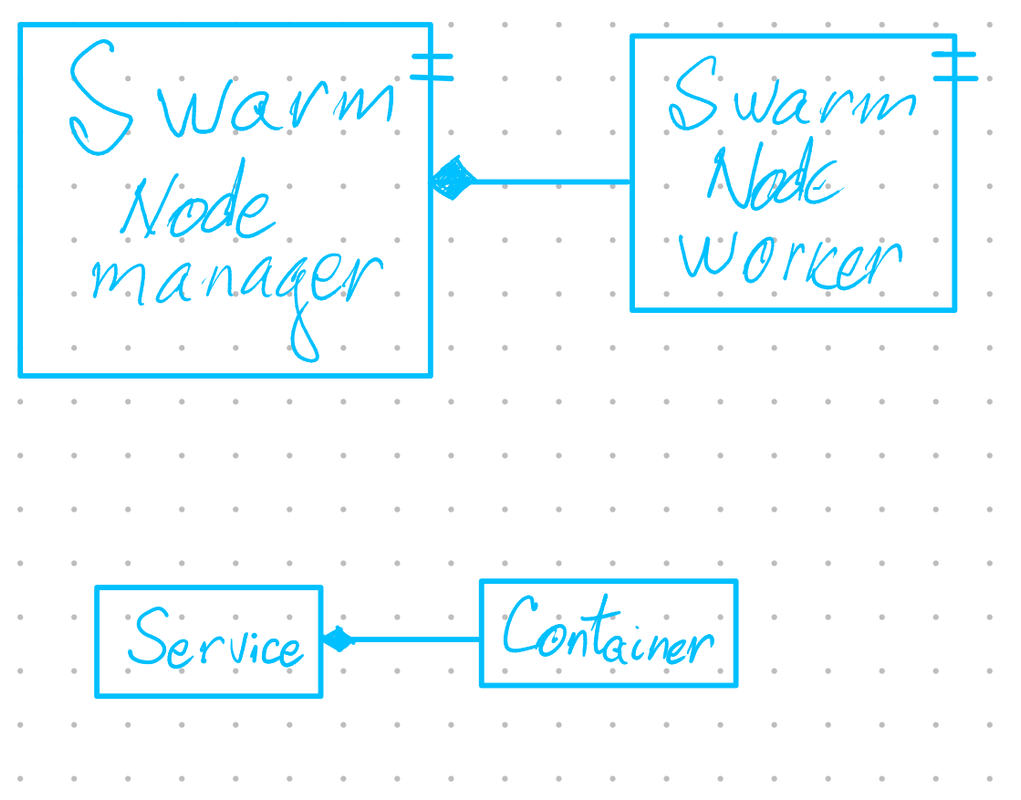
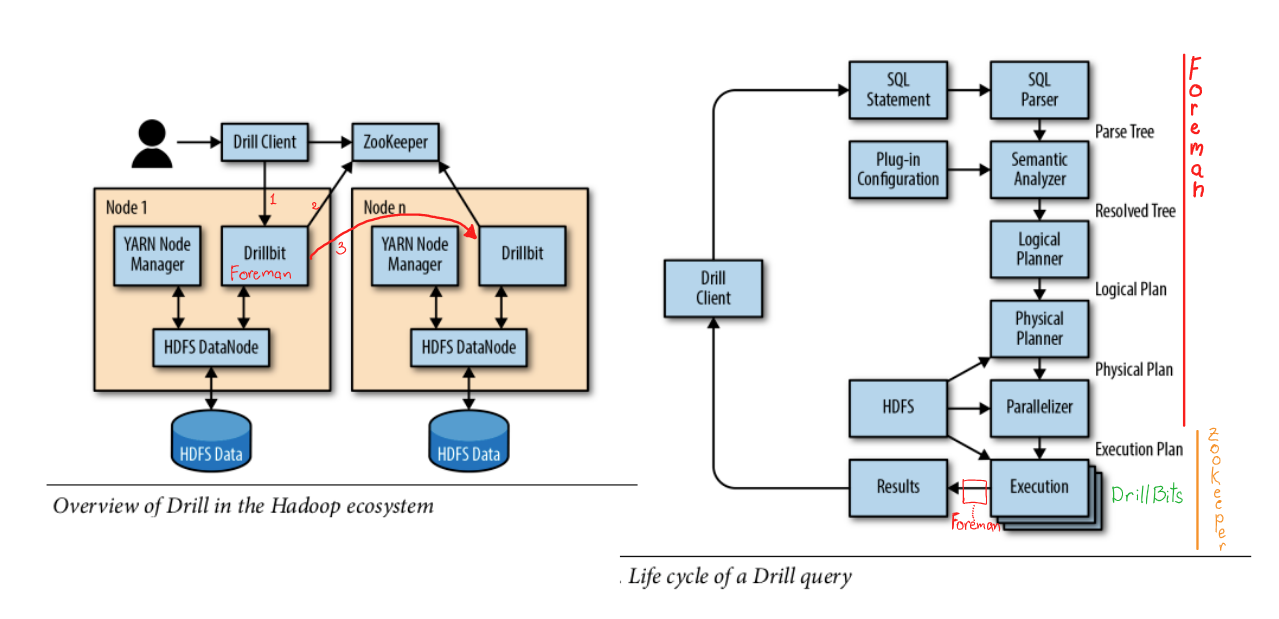


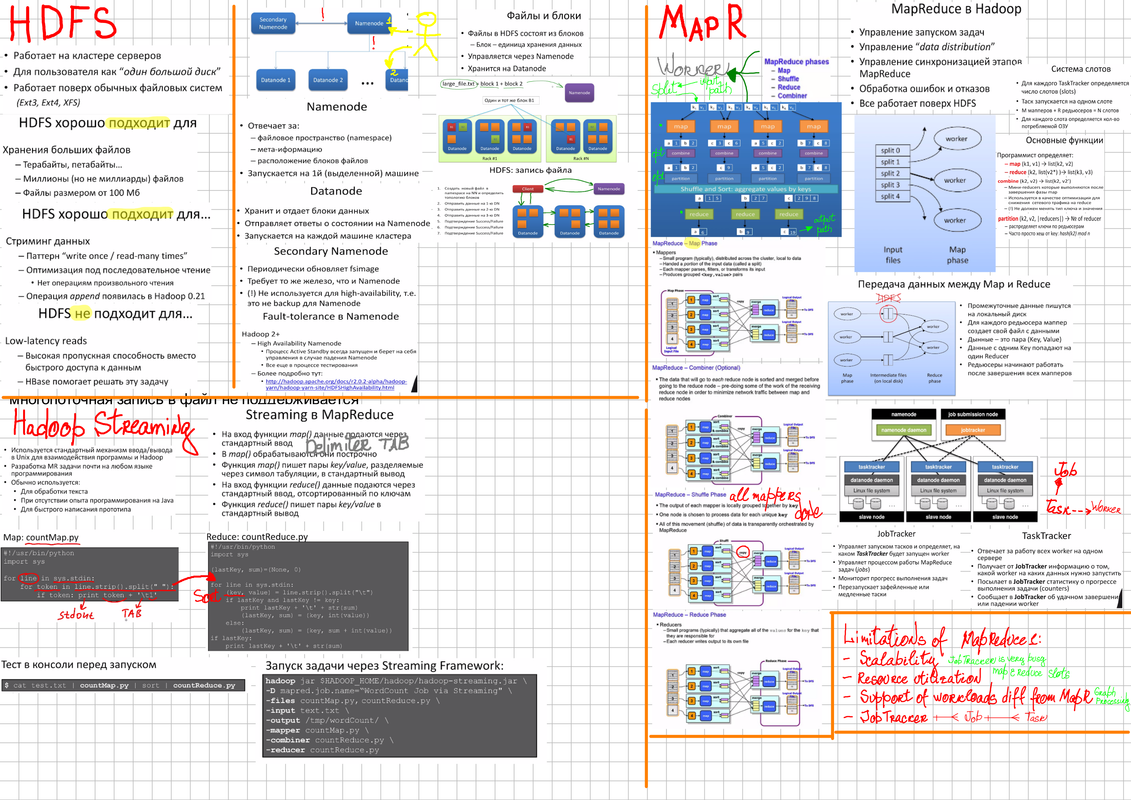



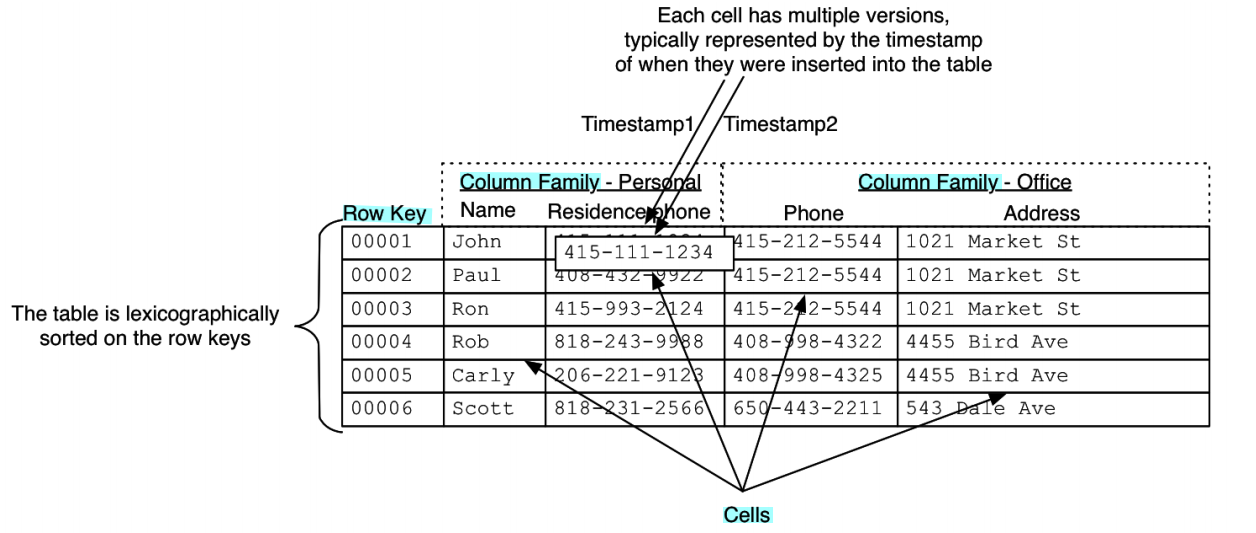
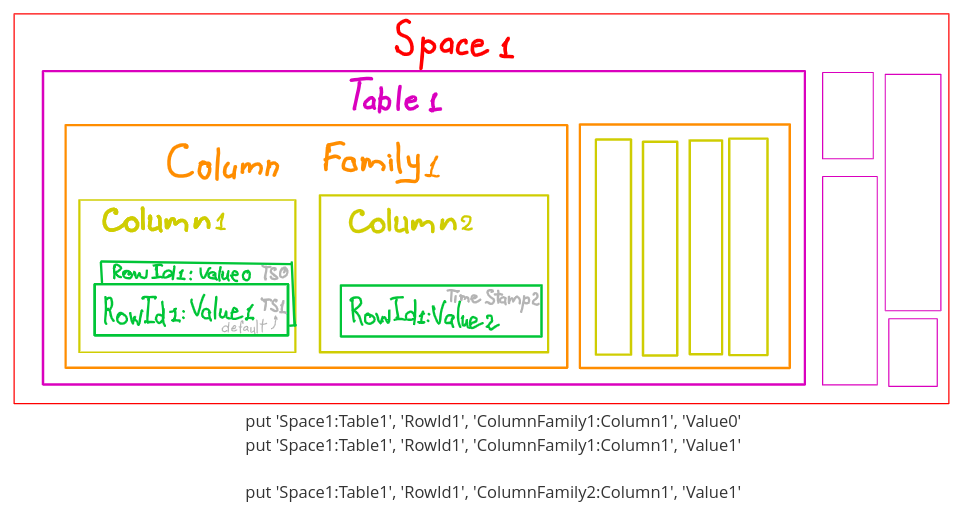












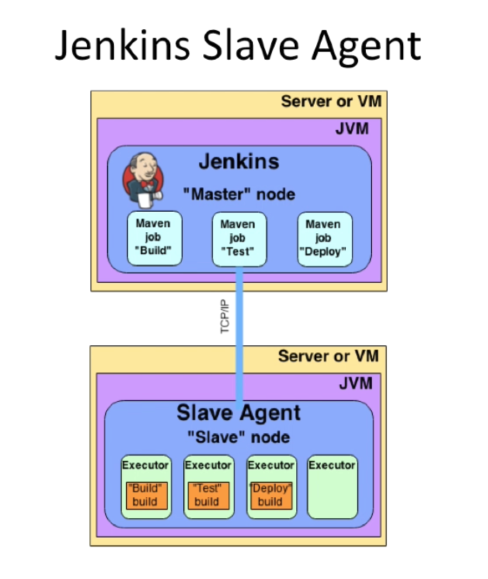
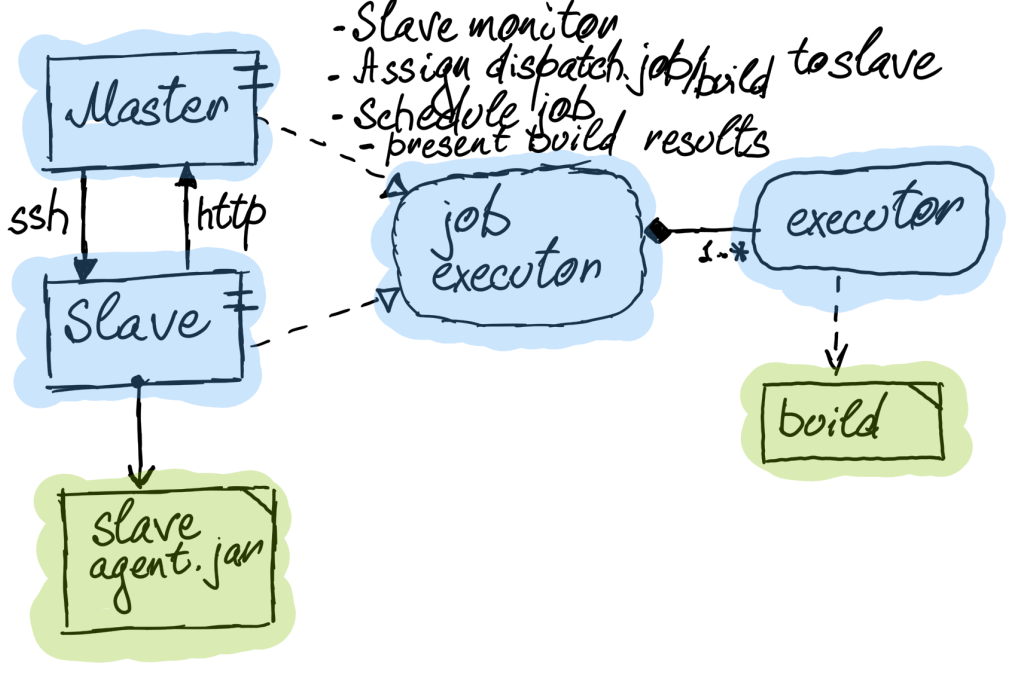


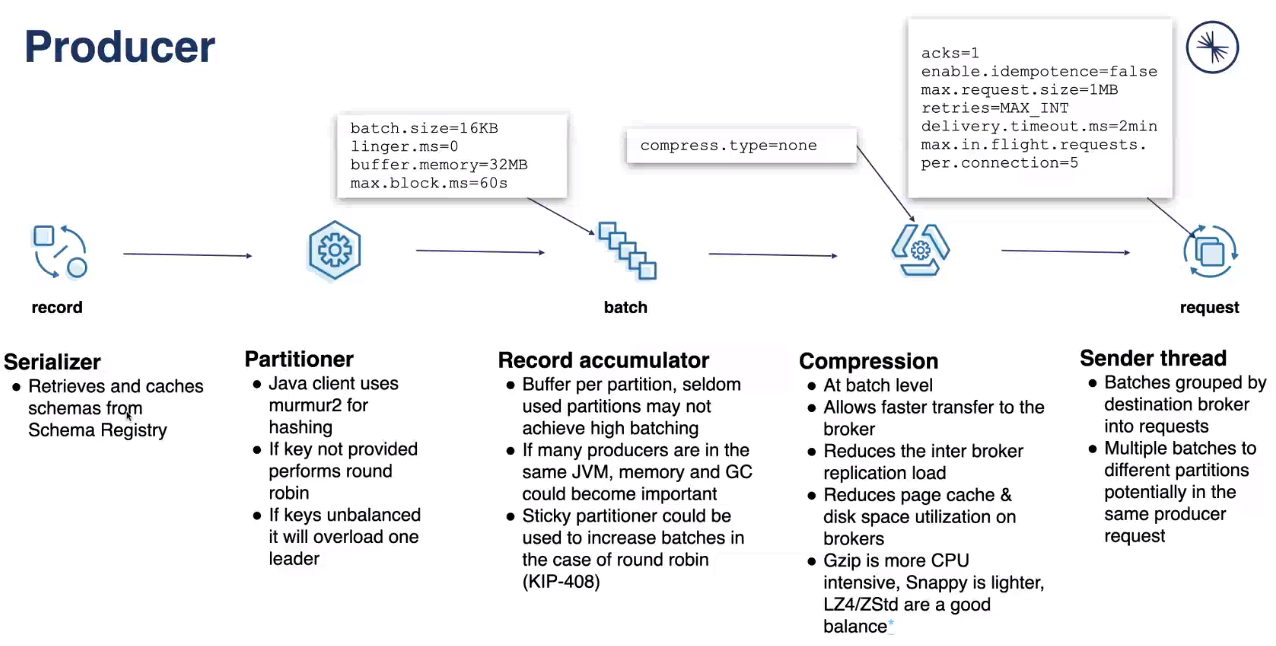
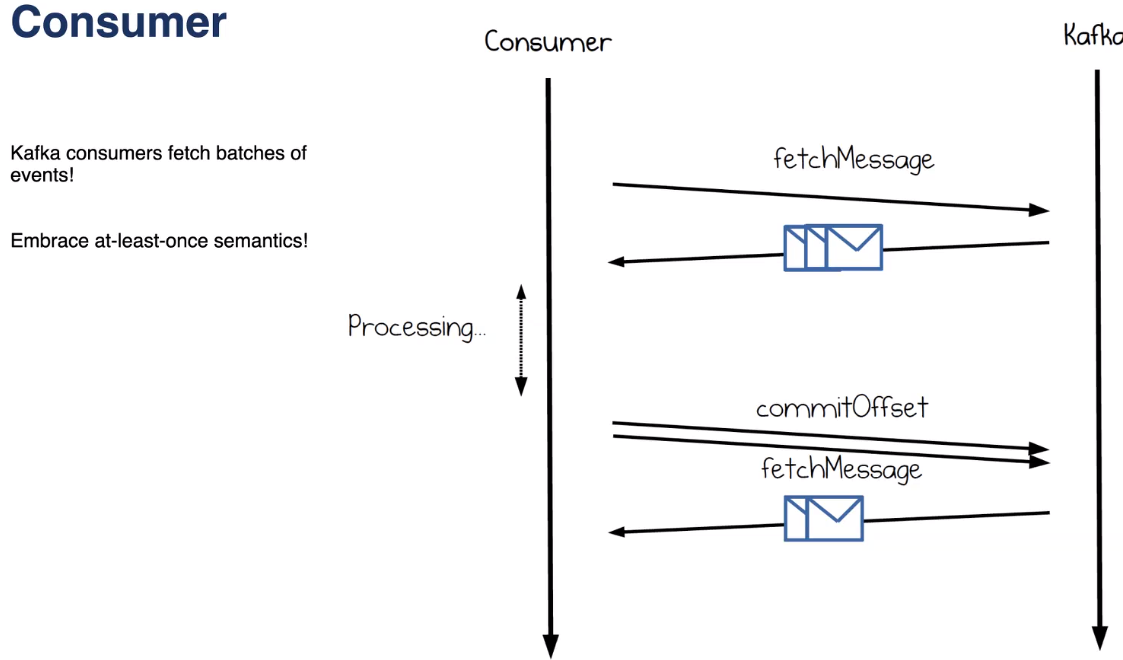
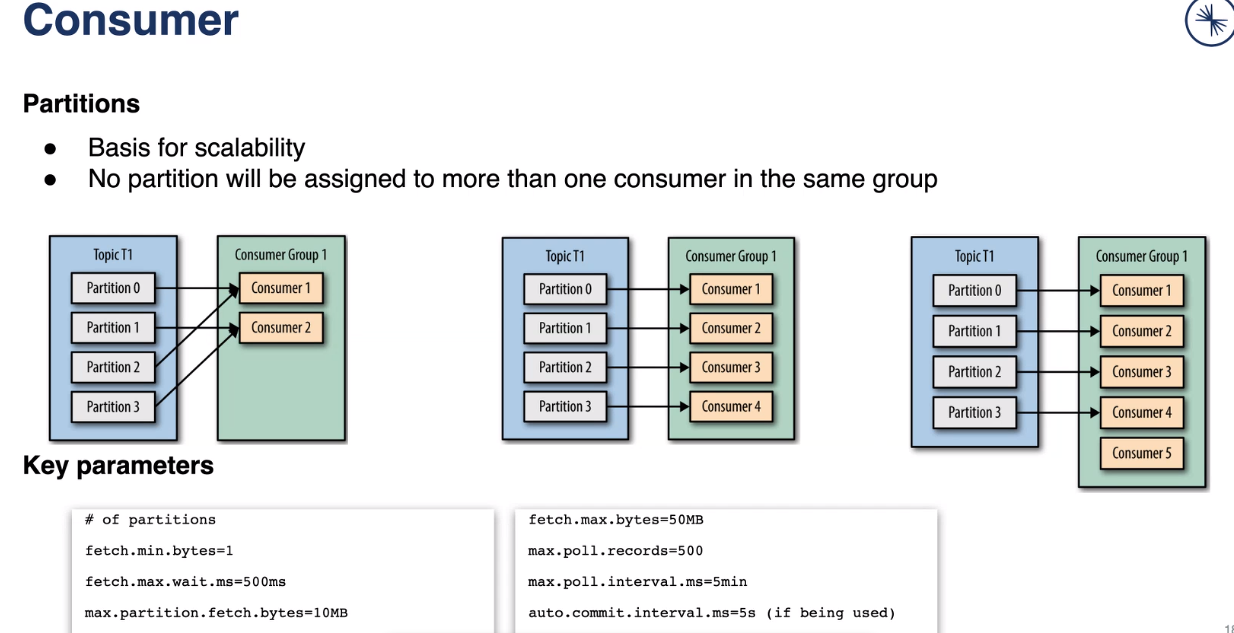
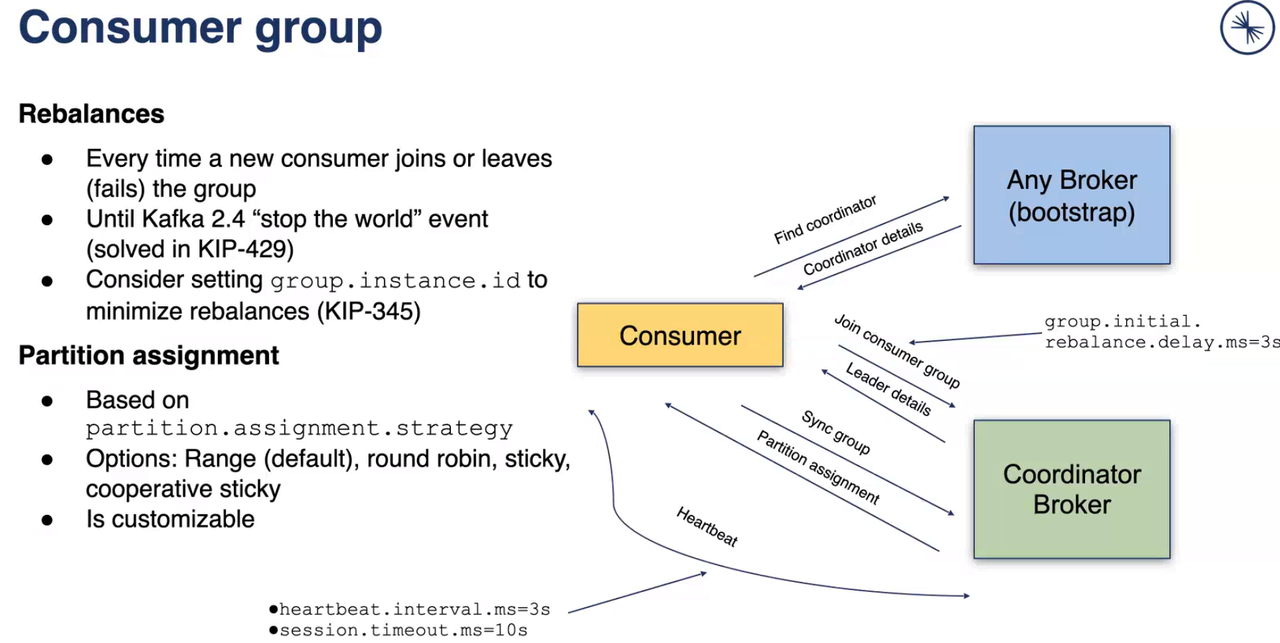
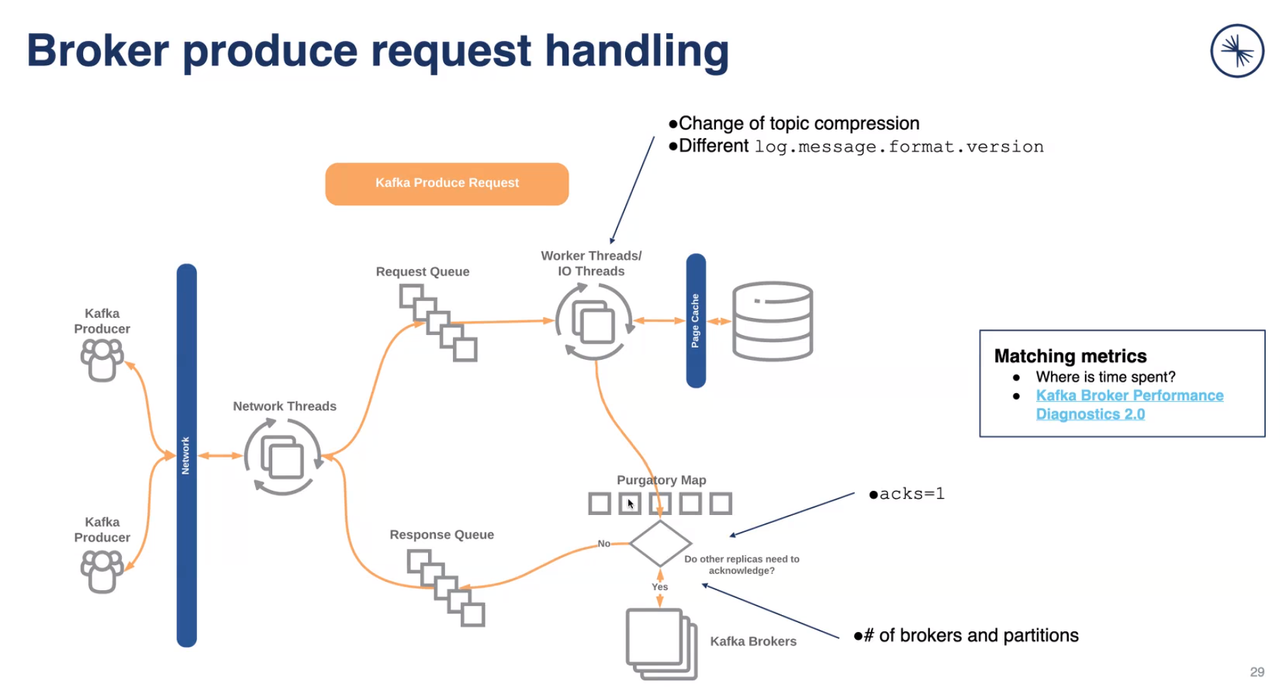


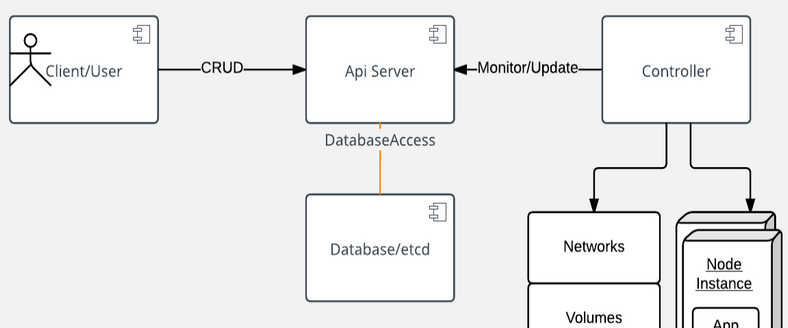
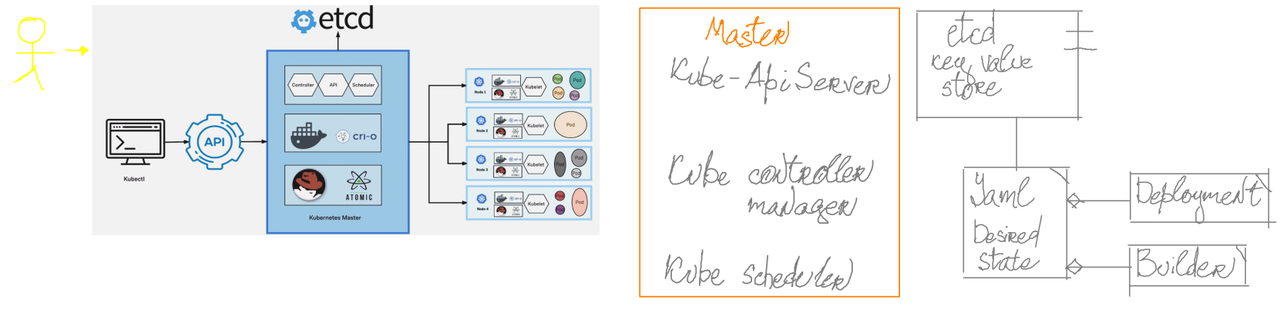
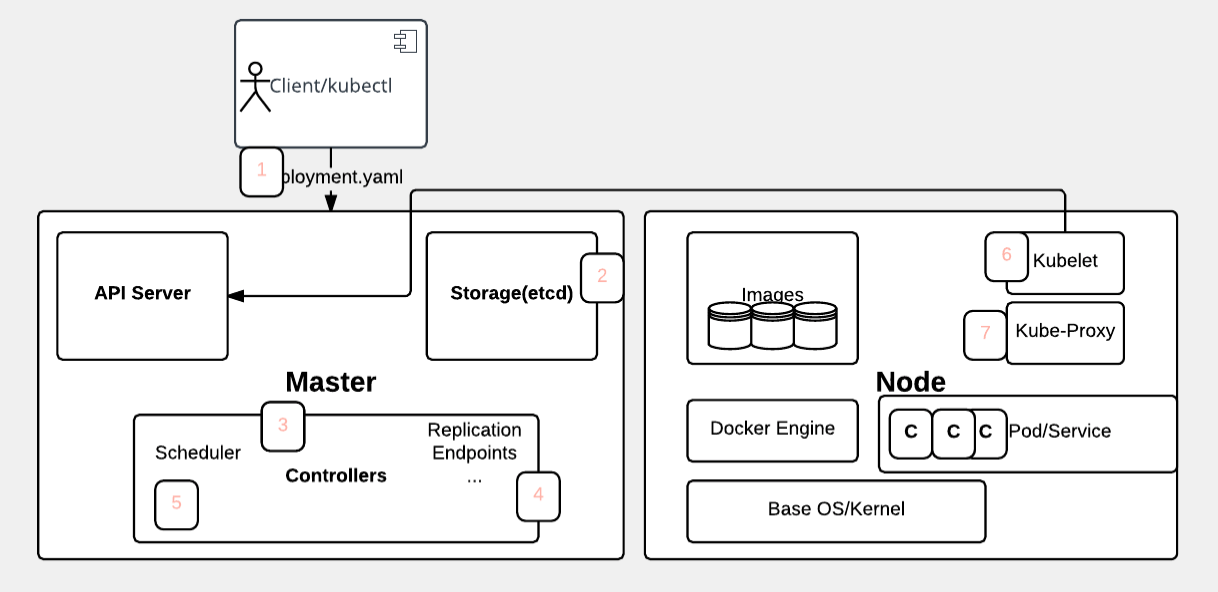
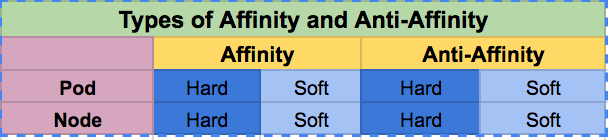
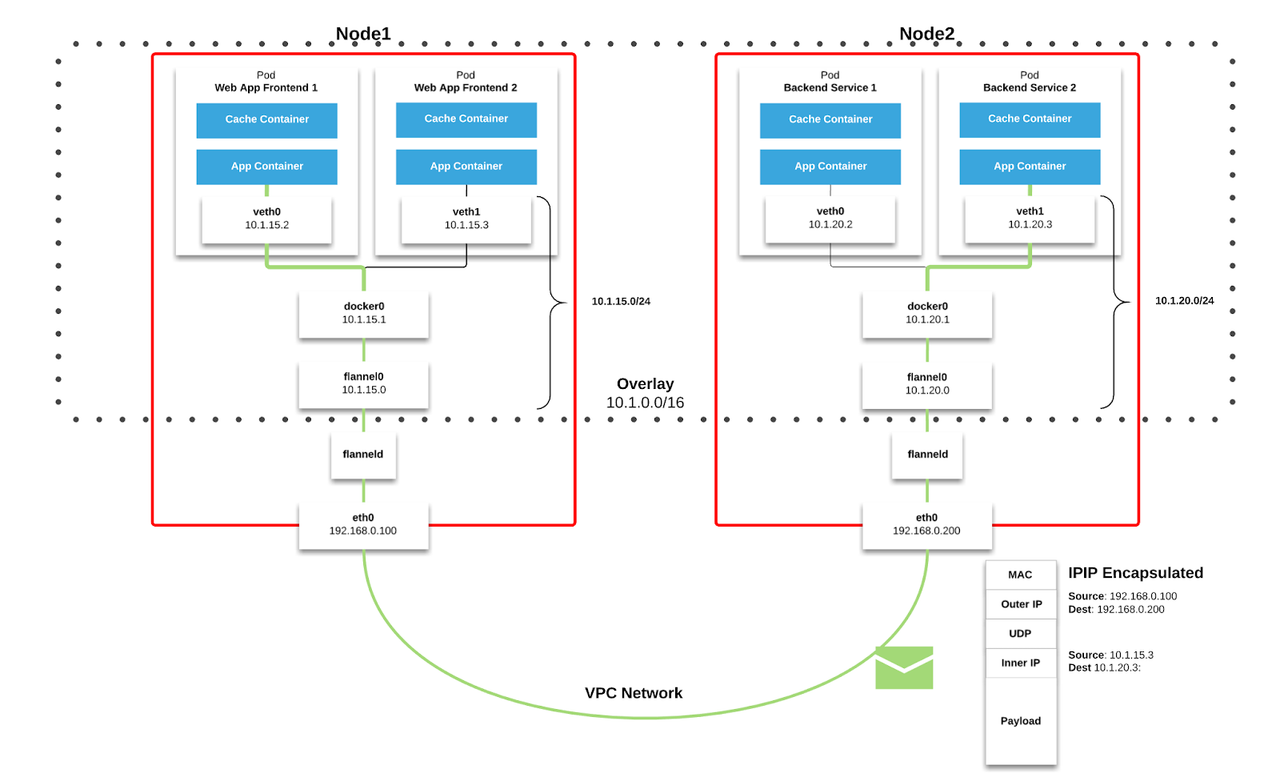



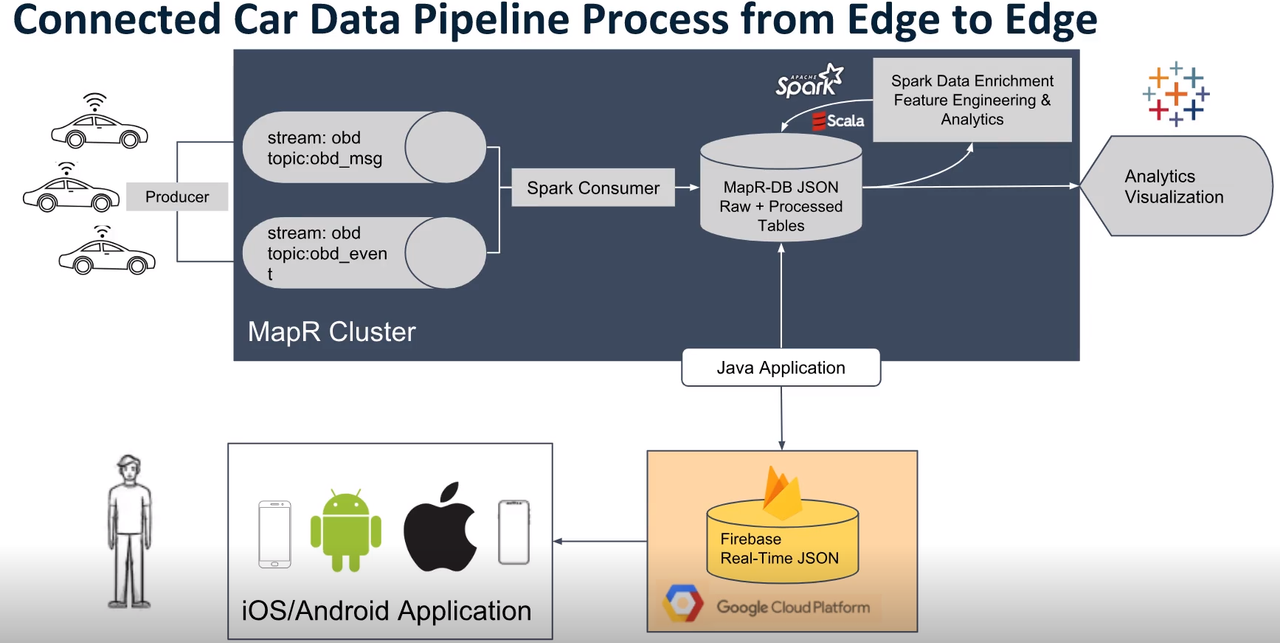
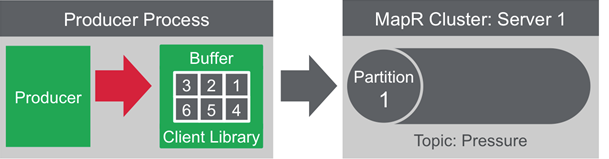
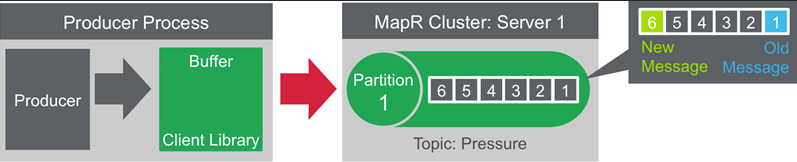
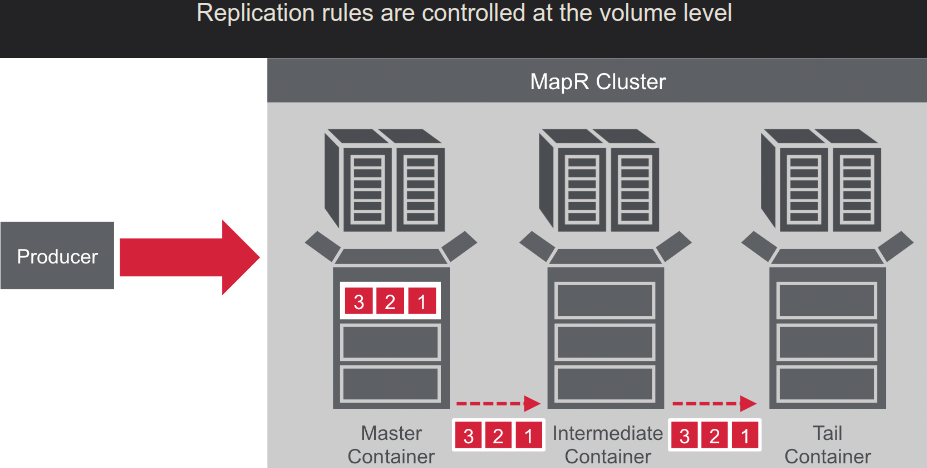
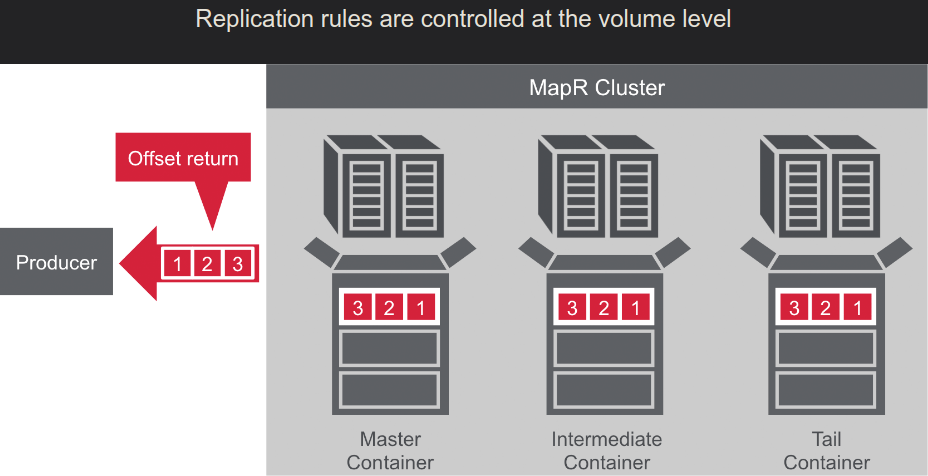




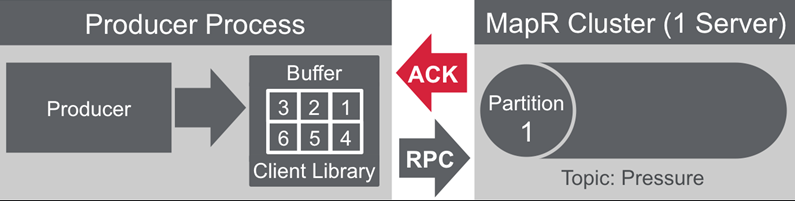






{kind=link}